Applications of Linear Alebra: PCA¶
We will explore 3 applications of linear algebra in data analysis - change of basis (for dimension reduction), projections (for solving linear systems) and the quadratic form (for optimization). The first applicaiotn is the change of basis to the eigenvector basis that underlies Principal Components Analysis s(PCA).
We wil review the following in class:
- The standard basis
- Orthonormal basis and orthgonal matrics
- Change of basis
- Similar matrices
- Eigendecomposiiotn
- Sample covariance
- Covariance as a linear transform
- PCA and dimension reduction
- PCA and “explained variance”
- SVD
Variance and covariance¶
Remember the formula for covariance
where \(\text{Cov}(X, X)\) is the sample variance of \(X\).
In [1]:
def cov(x, y):
"""Returns coaraiance of vectors x and y)."""
xbar = x.mean()
ybar = y.mean()
return np.sum((x - xbar)*(y - ybar))/(len(x) - 1)
In [2]:
X = np.random.random(10)
Y = np.random.random(10)
In [3]:
np.array([[cov(X, X), cov(X, Y)], [cov(Y, X), cov(Y,Y)]])
Out[3]:
array([[ 0.10527658, -0.00057506],
[-0.00057506, 0.0564982 ]])
In [4]:
# This can of course be calculated using numpy's built in cov() function
np.cov(X, Y)
Out[4]:
array([[ 0.10527658, -0.00057506],
[-0.00057506, 0.0564982 ]])
In [5]:
# Extension to more vairables is done in a pair-wise way
Z = np.random.random(10)
np.cov([X, Y, Z])
Out[5]:
array([[ 0.10527658, -0.00057506, 0.01746837],
[-0.00057506, 0.0564982 , 0.01549855],
[ 0.01746837, 0.01549855, 0.06009876]])
Eigendecomposition of the covariance matrix¶
In [6]:
mu = [0,0]
sigma = [[0.6,0.2],[0.2,0.2]]
n = 1000
x = np.random.multivariate_normal(mu, sigma, n).T
In [7]:
A = np.cov(x)
In [8]:
m = np.array([[1,2,3],[6,5,4]])
ms = m - m.mean(1).reshape(2,1)
np.dot(ms, ms.T)/2
Out[8]:
array([[ 1., -1.],
[-1., 1.]])
In [9]:
e, v = np.linalg.eig(A)
In [10]:
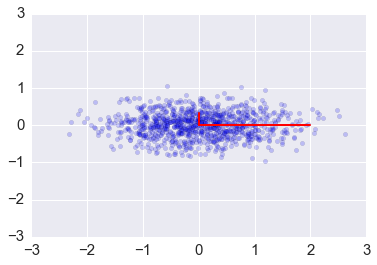
plt.scatter(x[0,:], x[1,:], alpha=0.2)
for e_, v_ in zip(e, v.T):
plt.plot([0, 3*e_*v_[0]], [0, 3*e_*v_[1]], 'r-', lw=2)
plt.axis([-3,3,-3,3])
plt.title('Eigenvectors of covariance matrix scaled by eigenvalue.');
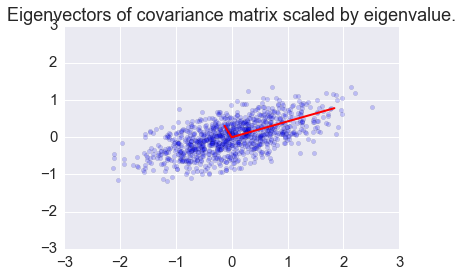
Covariance matrix as a linear transformation¶
The covariance matrix is a linear transofrmation that maps \(\mathbb{R}^n\) in the direction of its eigenvectors with scaling factor given by the eigenvlaues. Here we see it applied to a colleciton onf random vectors in the box bounded by [-1, 1].
We will assume we have a covariance matrix¶
In [11]:
covx = np.array([[1,0.6],[0.6,1]])
Create random vactors in a box¶
In [12]:
u = np.random.uniform(-1, 1, (100, 2)).T
Apply covariance matrix as linear transofrmation¶
In [13]:
y = covx @ u
In [14]:
e1, v1 = np.linalg.eig(covx)
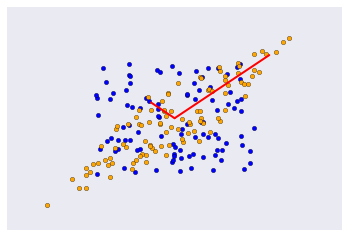
The linear transoform maps the radnom vectors as described.¶
In [15]:
plt.scatter(u[0], u[1], c='blue')
plt.scatter(y[0], y[1], c='orange')
for e_, v_ in zip(e1, v1.T):
plt.plot([0, e_*v_[0]], [0, e_*v_[1]], 'r-', lw=2)
plt.xticks([])
plt.yticks([])
pass
PCA¶
Principal Components Analysis (PCA) basically means to find and rank all the eigenvalues and eigenvectors of a covariance matrix. This is useful because high-dimensional data (with \(p\) features) may have nearly all their variation in a small number of dimensions \(k\), i.e. in the subspace spanned by the eigenvectors of the covariance matrix that have the \(k\) largest eigenvalues. If we project the original data into this subspace, we can have a dimension reduction (from \(p\) to \(k\)) with hopefully little loss of information.
Numerically, PCA is typically done using SVD on the data matrix rather than eigendecomposition on the covariance matrix. The next section explains why this works.
Data matrices that have zero mean for all feature vectors¶
and so the covariance matrix for a data set X that has zero mean in each feature vector is just \(XX^T/(n-1)\).
In other words, we can also get the eigendecomposition of the covariance matrix from the positive semi-definite matrix \(XX^T\).
Note that zeroing the feature vector does not affect the covariacne matrix¶
In [16]:
np.set_printoptions(precision=3)
In [17]:
X = np.random.random((5,4))
X
Out[17]:
array([[ 0.409, 0.456, 0.49 , 0.879],
[ 0.696, 0.434, 0.98 , 0.373],
[ 0.303, 0.987, 0.607, 0.03 ],
[ 0.781, 0.569, 0.211, 0.981],
[ 0.928, 0.417, 0.553, 0.686]])
In [18]:
### Subtract the row mean from each row
In [19]:
Y = X - X.mean(1)[:, None]
In [20]:
Y.mean(1)
Out[20]:
array([ 5.551e-17, -5.551e-17, 0.000e+00, 0.000e+00, 5.551e-17])
In [21]:
Y
Out[21]:
array([[-0.149, -0.103, -0.069, 0.321],
[ 0.076, -0.187, 0.359, -0.248],
[-0.179, 0.506, 0.125, -0.452],
[ 0.146, -0.067, -0.424, 0.345],
[ 0.282, -0.229, -0.093, 0.04 ]])
In [22]:
### Calculate the covariance
In [23]:
np.cov(X)
Out[23]:
array([[ 0.047, -0.032, -0.06 , 0.042, 0. ],
[-0.032, 0.077, 0.016, -0.071, 0.007],
[-0.06 , 0.016, 0.169, -0.09 , -0.065],
[ 0.042, -0.071, -0.09 , 0.108, 0.036],
[ 0. , 0.007, -0.065, 0.036, 0.047]])
In [24]:
np.cov(Y)
Out[24]:
array([[ 0.047, -0.032, -0.06 , 0.042, 0. ],
[-0.032, 0.077, 0.016, -0.071, 0.007],
[-0.06 , 0.016, 0.169, -0.09 , -0.065],
[ 0.042, -0.071, -0.09 , 0.108, 0.036],
[ 0. , 0.007, -0.065, 0.036, 0.047]])
Eigendecomposition of the covariance matrix¶
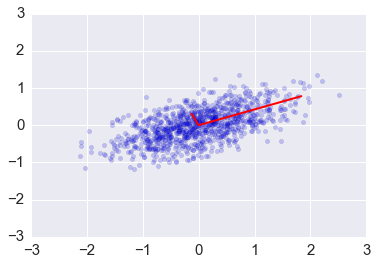
In [25]:
e1, v1 = np.linalg.eig(np.dot(x, x.T)/(n-1))
In [26]:
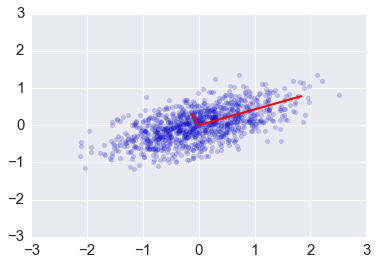
plt.scatter(x[0,:], x[1,:], alpha=0.2)
for e_, v_ in zip(e1, v1.T):
plt.plot([0, 3*e_*v_[0]], [0, 3*e_*v_[1]], 'r-', lw=2)
plt.axis([-3,3,-3,3]);
Change of basis via PCA¶
We can transform the original data set so that the eigenvectors are the basis vectors amd find the new coordinates of the data points with respect to this new basis¶
This is the change of basis transformation covered in the Linear Alegebra module. First, note that the covariance matrix is a real symmetric matrix, and so the eigenvector matrix is an orthogonal matrix.
In [27]:
e, v = np.linalg.eig(np.cov(x))
v.dot(v.T)
Out[27]:
array([[ 1., 0.],
[ 0., 1.]])
Linear algebra review for change of basis¶
Graphical illustration of change of basis¶
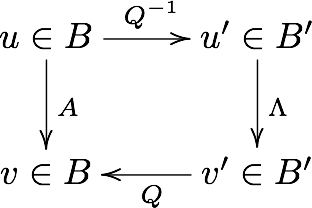
Commuative diagram
Suppose we have a vector \(u\) in the standard basis \(B\) , and a matrix \(A\) that maps \(u\) to \(v\), also in \(B\). We can use the eigenvalues of \(A\) to form a new basis \(B'\). As explained above, to bring a vector \(u\) from \(B\)-space to a vector \(u'\) in \(B'\)-space, we multiply it by \(Q^{-1}\), the inverse of the matrix having the eigenvctors as column vectors. Now, in the eignvector basis, the equivalent operation to \(A\) is the diagonal matrix \(\Lambda\) - this takes \(u'\) to \(v'\). Finally, we convert \(v'\) back to avector \(v\) in the standard basis by multiplying with \(Q\).
In [28]:
ys = np.dot(v1.T, x)
Principal components are simply the eigenvectors of the coveriance matrix used as basis vectors. Each of the origainl data points is expreessed as a linear combination of the principal components, giving rise to a new set of coordinates.
In [29]:
plt.scatter(ys[0,:], ys[1,:], alpha=0.2)
for e_, v_ in zip(e1, np.eye(2)):
plt.plot([0, 3*e_*v_[0]], [0, 3*e_*v_[1]], 'r-', lw=2)
plt.axis([-3,3,-3,3]);
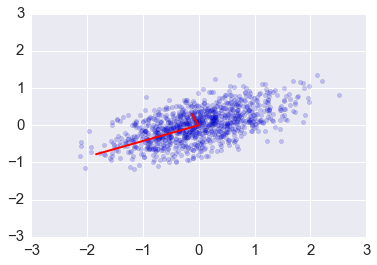
For example, if we only use the first column of ys, we will have the
projection of the data onto the first principal component, capturing the
majoriyt of the variance in the data with a single featrue that is a
linear combination of the original features.
We may need to transform the (reduced) data set to the original feature coordinates for interpreation. This is simply another linear transform (matrix multiplication).
In [30]:
zs = np.dot(v1, ys)
In [31]:
plt.scatter(zs[0,:], zs[1,:], alpha=0.2)
for e_, v_ in zip(e1, v1.T):
plt.plot([0, 3*e_*v_[0]], [0, 3*e_*v_[1]], 'r-', lw=2)
plt.axis([-3,3,-3,3]);
In [32]:
u, s, v = np.linalg.svd(x)
u.dot(u.T)
Out[32]:
array([[ 1.000e+00, -5.551e-17],
[ -5.551e-17, 1.000e+00]])
Dimension reduction via PCA¶
We have the sepctral decomposition of the covariance matrix
Suppose \(\Lambda\) is a rank \(p\) matrix. To reduce the dimensionality to \(k \le p\), we simply set all but the first \(k\) values of the diagonal of \(\Lambda\) to zero. This is equivvalent to ignoring all except the first \(k\) principal componnents.
What does this achieve? Recall that \(A\) is a covariance matrix, and the trace of the matrix is the overall variability, since it is the sum of the variances.
In [33]:
A
Out[33]:
array([[ 0.581, 0.2 ],
[ 0.2 , 0.196]])
In [34]:
A.trace()
Out[34]:
0.77708078173456197
In [35]:
e, v = np.linalg.eig(A)
D = np.diag(e)
D
Out[35]:
array([[ 0.666, 0. ],
[ 0. , 0.111]])
In [36]:
D.trace()
Out[36]:
0.77708078173456208
In [37]:
D[0,0]/D.trace()
Out[37]:
0.8571202702924946
Since the trace is invariant under change of basis, the total variability is also unchaged by PCA. By keeping only the first \(k\) principal components, we can still “explain” \(\sum_{i=1}^k e[i]/\sum{e}\) of the total variability. Sometimes, the degree of dimension reduction is specified as keeping enough principal components so that (say) \(90\%\) fo the total variability is exlained.
Using Singular Value Decomposition (SVD) for PCA¶
SVD is a decomposition of the data matrix \(X = U S V^T\) where \(U\) and \(V\) are orthogonal matrices and \(S\) is a diagnonal matrix.
Recall that the transpose of an orthogonal matrix is also its inverse, so if we multiply on the right by \(X^T\), we get the follwoing simplification
Compare with the eigendecomposition of a matrix \(A = W \Lambda W^{-1}\), we see that SVD gives us the eigendecomposition of the matrix \(XX^T\), which as we have just seen, is basically a scaled version of the covariance for a data matrix with zero mean, with the eigenvectors given by \(U\) and eigenvealuse by \(S^2\) (scaled by \(n-1\))..
In [38]:
u, s, v = np.linalg.svd(x)
In [39]:
e2 = s**2/(n-1)
v2 = u
plt.scatter(x[0,:], x[1,:], alpha=0.2)
for e_, v_ in zip(e2, v2):
plt.plot([0, 3*e_*v_[0]], [0, 3*e_*v_[1]], 'r-', lw=2)
plt.axis([-3,3,-3,3]);
In [40]:
v1 # from eigenvectors of covariance matrix
Out[40]:
array([[ 0.921, -0.391],
[ 0.391, 0.921]])
In [41]:
v2 # from SVD
Out[41]:
array([[-0.921, -0.391],
[-0.391, 0.921]])
In [42]:
e1 # from eigenvalues of covariance matrix
Out[42]:
array([ 0.666, 0.111])
In [43]:
e2 # from SVD
Out[43]:
array([ 0.666, 0.111])
In [44]:
a0 = np.random.normal(0,1,100)
a1 = a0 + np.random.normal(0,3,100)
a2 = 2*a0 + a1 + np.random.normal(5,0.01,100)
xs = np.vstack([a0, a1, a2])
xs.shape
Out[44]:
(3, 100)
In [45]:
C = np.cov(xs)
In [46]:
C
Out[46]:
array([[ 0.927, 1.037, 2.888],
[ 1.037, 9.385, 11.459],
[ 2.888, 11.459, 17.232]])
In [47]:
e, v = np.linalg.eig(C)
In [48]:
v
Out[48]:
array([[-0.118, -0.816, 0.566],
[-0.574, -0.409, -0.71 ],
[-0.81 , 0.409, 0.42 ]])
In [49]:
U, s, V = np.linalg.svd(xs)
In [50]:
(s**2)/(99)
Out[50]:
array([ 42.417, 6.138, 0.74 ])
In [51]:
U
Out[51]:
array([[-0.066, 0.043, 0.997],
[-0.302, 0.951, -0.061],
[-0.951, -0.305, -0.05 ]])
In [52]:
np.round(e/e.sum(), 4)
Out[52]:
array([ 0.936, 0. , 0.064])
In [53]:
ys = np.linalg.inv(v).dot(xs)
In [54]:
plt.scatter(ys[0,:], ys[2,:])
pass
In [55]:
zs = v[:, [0,2]].dot(ys[[0,2],:])
zs.shape
Out[55]:
(3, 100)
In [56]:
v[:, [0,2]]
Out[56]:
array([[-0.118, 0.566],
[-0.574, -0.71 ],
[-0.81 , 0.42 ]])
In [57]:
plt.figure(figsize=(12.,4))
plt.subplot(1,3,1)
plt.scatter(zs[0,:], zs[1,:])
plt.subplot(1,3,2)
plt.scatter(zs[0,:], zs[2,:])
plt.subplot(1,3,3)
plt.scatter(zs[1,:], zs[2,:])
pass
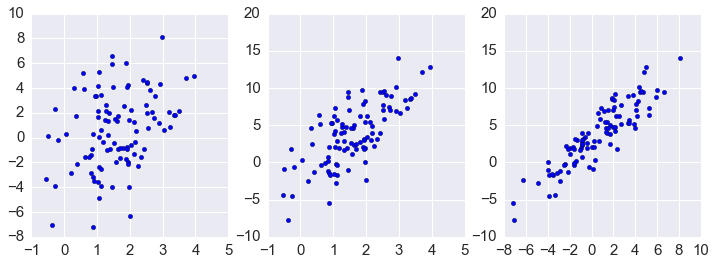
In [58]:
plt.figure(figsize=(12.,4))
plt.subplot(1,3,1)
plt.scatter(xs[0,:], xs[1,:])
plt.subplot(1,3,2)
plt.scatter(xs[0,:], xs[2,:])
plt.subplot(1,3,3)
plt.scatter(xs[1,:], xs[2,:])
pass
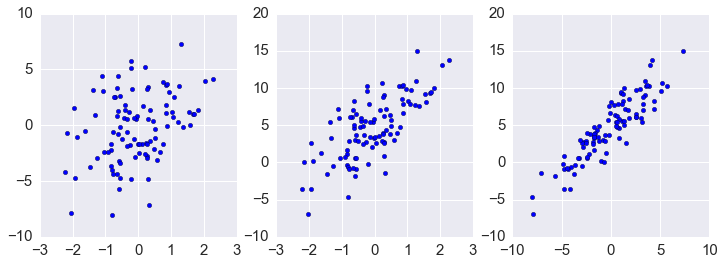
In [59]:
plt.figure(figsize=(12.,4))
plt.subplot(1,3,1)
plt.scatter(ys[0,:], ys[1,:])
plt.subplot(1,3,2)
plt.scatter(ys[0,:], ys[2,:])
plt.subplot(1,3,3)
plt.scatter(ys[1,:], ys[2,:])
pass