Using Auxiliary Variables in MCMC proposals¶
Slice sampling¶
Slice sampling is a simple MCMC algorithm that introudces the idea of auxiliary variables. The motivation for slice sampling is that if we can sample uniformly from the region under the graph of the target distribution, we will have random samples from the target distribution. In the univariate case, the algorithm is as follows
- start with some \(x\) where \(p(x) \ne 0\)
- repeat
- sample \(y\) (auxiliary variable) uniformly from 0 to \(f(x)\)
- draw a horizontal line at \(y\) within \(p(x)\) (this may consist of multiple intervals)
- sample \(x\) from the horizontal segments
The auxiliary \(y\) variable allows us to sample \((x, y)\) points that are in the region under the graph of the target distribution. Only the \(x\) variable is used for the Monte Carlo samples - the \(y\) variables are simply discarded. This works because the joint disribution is constructed so that it factors \(p(x, y) = p(y \mid x) p(x)\) and so projecting leaves just \(p(x)\). The slice sampler is a Markov Chain Monte Carlo method since the next \((x, y)\) position depends only on the current position. Like Gibbs sampling, there is no tuning process and all proposals are accepted. For slice sampling, you either need the inverse distribution function or some way to estimate it. Later we will see that Hamiltonian Monte Carlo also uses auxiliary variables to generate a new proposal in an analogous way.
A toy example illustrates the process - Suppose we want to draw random samples from the posterior distribution \(\mathcal{N}(0, 1)\) using slice sampling
Start with some value \(x\) - sample \(y\) from \(\mathcal{U}(0, f(x))\) - this is the horizontal “slice” that gives the method its name - sample the next \(x\) from \(f^{-1}(y)\) - this is typically done numerically - repeat
Will sketch picture in class to show what is going on.
A simple slice sampler example¶
In [1]:
import scipy.stats as stats
In [2]:
dist = stats.norm(5, 3)
w = 0.5
x = dist.rvs()
niters = 1000
xs = []
while len(xs) < niters:
y = np.random.uniform(0, dist.pdf(x))
lb = x
rb = x
while y < dist.pdf(lb):
lb -= w
while y < dist.pdf(rb):
rb += w
x = np.random.uniform(lb, rb)
if y > dist.pdf(x):
if np.abs(x-lb) < np.abs(x-rb):
lb = x
else:
lb = y
else:
xs.append(x)
In [3]:
plt.hist(xs, 20)
pass

Notes on the slice sampler:
- the slice may consist of disjoint pieces for multimodal distributions
- the slice can be a rectangular hyperslab for multivariable posterior distributions
- sampling from the slice (i.e. finding the boundaries at level \(y\)) is non-trivial and may involve iterative rejection steps - see figure below (from Wikimedia) for a typical approach - the blue bars represent disjoint pieces of the true slice through a bimodal distribution and the black lines are the proposal distribution approximating the true slice
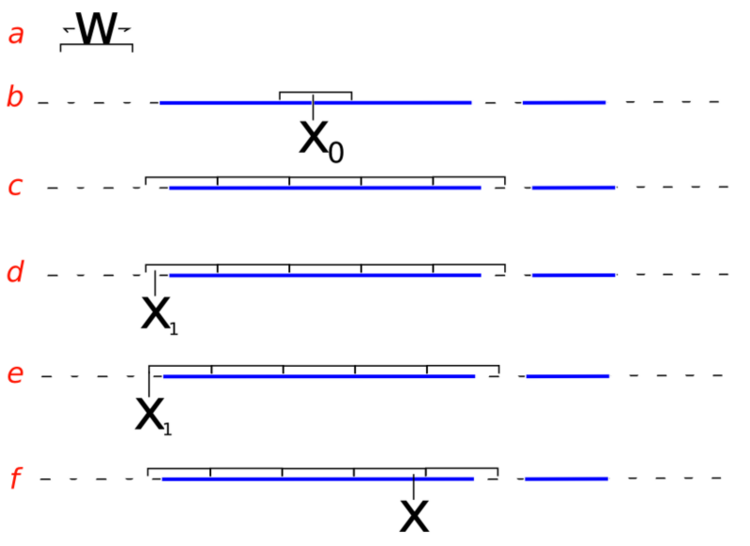
Slice sampling algorithm from Wikipedia
Hamiltonian Monte Carlo (HMC)¶
HMC uses an auxiliary variable corresponding to the momentum of particles in a potential energy well to generate proposal distributions that can make use of gradient information in the posterior distribution. For reversibility to be maintained, the total energy of the particle has to be conserved - hence we are interested in Hamiltonian systems. The main attraction of HMC is that it works much better than other methods when variables of interest are highly correlated. Because we have to solve problems involving momentum, we need to understand how to numerically solve differential equations in a way that is both accurate (i.e. second order) and preserves total energy (necessary for a Hamiltonian system).
Example adapted from MCMC: Hamiltonian Monte Carlo (a.k.a. Hybrid Monte Carlo)
Hamiltonian systems¶
In a Hamiltonian system, we consider particles with position \(x\) and momentum (or velocity if we assume unit mass) \(v\). The total energy of the system \(H(x, v) = K(v) + U(x)\), where \(K\) is the kinetic energy and \(U\) is the potential energy, is conserved. Such a system satisfies the following Hamiltonian equations
Since \(K\) depends only on \(v\) and \(U\) depends only on \(x\), we have
Harmonic oscillator¶
We will consider solving a classical Hamiltonian system - that of a undamped spring governed by the second order differential equation
We convert this to two first order ODEs by using a dummy variable \(x' = v\) to get
From the Hamiltonian equations above, this is equivalent to a system with kinetic energy \(K(v) = \frac{1}{2}v^2\) and potential energy \(U(x) = \frac{1}{2}x^2\).
Writing in matrix form,
and in general, for the state vector \(x\),
We note that \(A\) is anti- or skew-symmetric (\(A^T = -A\)), and hence has purely imaginary eigenvalues. Solving \(|A - \lambda I = 0\), we see that the eigenvalues and eigenvectors are \(i, \pmatrix{1\\i}\) and \(-i, \pmatrix{1\\-i}\). Since the eigenvalues are pure imaginary, we see that the solution for the initial conditions \((x,v) = (1, 0)\) is \(x(t) = e^{it}\) and the orbit just goes around a circle with a period of \(2\pi\), neither growing nor decaying. Another weay of seeing this is that the Hamiltonian \(H(u, v)\) or sum of potential (\(U(x)) = \frac{1}{2}x^2\)) and kinetic energy (\(K(v) = \frac{1}{2}v^2\)) is constant, i.e. in vector form, \((x^T x) = \text{constant}\).
Finite difference methods¶
We want to find a finite difference approximation to \(u' = Au\) that is accurate and preserves total energy. If total energy is not preserved, the orbit will either spiral in towards zero or outwards away from the unit circle. If the accuracy is poor, the orbit will not be close to its starting value after \(t = 2\pi\). This gives us an easy way to visualize how good our numerical scheme is. We can also compare the numerical scheme to the Taylor series to evaluate its accuracy.
Forward Euler¶
The simplest finite difference scheme for integrating ODEs is the forward Euler
Rearranging terms, we get
Since the eigenvalues of \(A\) are \(\pm i\), we see that the eigenvalues of the forward Euler matrix are \(1 \pm i\). Since the absolute value of the eigenvalues is greater than 1, we expect growing solutions - i.e. the solution will spiral away from the unit circle.
In [4]:
import scipy.linalg as la
In [5]:
def f_euler(A, u, N):
orbit = np.zeros((N,2))
dt = 2*np.pi/N
for i in range(N):
u = u + dt * A @ u
orbit[i] = u
return orbit
In [6]:
A = np.array([[0,1],[-1,0]])
u = np.array([1.0,0.0])
N = 64
orbit = f_euler(A, u, N)
Conservation of energy¶
In [8]:
plt.plot([p @ p for p in orbit])
pass

In [9]:
ax = plt.subplot(111)
plt.plot(orbit[:, 0], orbit[:,1], 'o')
ax.axis('square')
plt.axis([-1.5, 1.5, -1.5, 1.5])
pass

Accuracy and conservation of energy¶
We can see that forward Euler is not very accurate and also does not preserve energy since the orbit spirals away from the unit circle.
The trapezoidal method¶
The trapezoidal method uses the following scheme
This is an implicit scheme (because \(u_{n+1}\) appears on the RHS) whose solution is
By inspection, we see that the eigenvalues are the complex conjugates of
whose absolute value is 1 - hence, energy is conserved. If we expand the matrix \(B\) using the geometric series and compare with the Taylor expansion, we see that the trapezoidal method has local truncation error \(O(h^3)\) and hence accuracy \(O(h^2)\), where \(h\) is the time step.
In [10]:
def trapezoidal(A, u, N):
p = len(u)
orbit = np.zeros((N,p))
dt = 2*np.pi/N
for i in range(N):
u = la.inv(np.eye(p) - dt/2 * A) @ (np.eye(p) + dt/2 * A) @ u
orbit[i] = u
return orbit
In [11]:
A = np.array([[0,1],[-1,0]])
u = np.array([1.0,0.0])
N = 64
orbit = trapezoidal(A, u, N)
Conservation of energy¶
In [13]:
plt.plot([p @ p for p in orbit])
pass

In [14]:
ax = plt.subplot(111)
plt.plot(orbit[:, 0], orbit[:,1], 'o')
ax.axis('square')
plt.axis([-1.5, 1.5, -1.5, 1.5])
pass

The leapfrog method¶
The leapfrog method uses a second order difference to update \(u_n\). The algorithm simplifies to the following explicit scheme:
- First take one half-step for v
- Then take a full step for u
- Then take one final half step for v
It performs as well as the trapezoidal method, with the advantage of being an explicit scheme and cheaper to calculate, so the leapfrog method is used in HMC.
In [15]:
def leapfrog(A, u, N):
orbit = np.zeros((N,2))
dt = 2*np.pi/N
for i in range(N):
u[1] = u[1] + dt/2 * A[1] @ u
u[0] = u[0] + dt * A[0] @ u
u[1] = u[1] + dt/2 * A[1] @ u
orbit[i] = u
return orbit
If we don’t care about the intermediate steps, it is more efficient to just take 1/2 steps at the beginning and end¶
In [16]:
def leapfrog2(A, u, N):
dt = 2*np.pi/N
u[1] = u[1] + dt/2 * A[1] @ u
for i in range(N-1):
u[0] = u[0] + dt * A[0] @ u
u[1] = u[1] + dt * A[1] @ u
u[0] = u[0] + dt * A[0] @ u
u[1] = u[1] + dt/2 * A[1] @ u
return u
In [17]:
A = np.array([[0,1],[-1,0]])
u = np.array([1.0,0.0])
N = 64
In [18]:
orbit = leapfrog(A, u, N)
Conservation of energy¶
In [20]:
plt.plot([p @ p for p in orbit])
pass

In [21]:
ax = plt.subplot(111)
plt.plot(orbit[:, 0], orbit[:,1], 'o')
ax.axis('square')
plt.axis([-1.5, 1.5, -1.5, 1.5])
pass

From Hamiltonians to probability distributions¶
The physical analogy considers the negative log likelihood of the target distribution \(p(x)\) to correspond to a potential energy well, with a collection of particles moving on the surface of the well. The state of each particle is given only by its position and momentum (or velocity if we assume unit mass for each particle). In a Hamiltonian system, the total energy \(H(x,, v) = U(x) + K(v)\) is conserved. From statistical mechanics, the probability of each state is related to the total energy of the system
Since the joint distribution factorizes \(p(x, v) = p(x)\, p(v)\), we can select an initial random \(v\) for a particle, numerically integrate using a finite difference method such as the leapfrog and then use the updated \(x^*\) as the new proposal. The acceptance ratio for the new \(x^*\) is
If our finite difference scheme was exact, the acceptance ration would be 1 since energy is conserved with Hamiltonian dynamics. However, as we have seen, the leapfrog method does not conserve energy perfectly and an accept/reject step is still needed.
Example of HMC¶
We will explore how HMC works when the target distribution is bivariate normal centered at zero
In practice of course, the target distribution will be the posterior distribution and depend on both data and distributional parameters.
The potential energy or negative log likelihood is proportional to
The kinetic energy is given by
where the initial \(v_0\) is chosen at random from the unit normal at each step.
To find the time updates, we use the Hamiltonian equations and find the first derivatives of total energy with respect to \(x\) and \(v\)
giving us the block matrix
By using the first derivatives, we are making use of the gradient information on the log posterior to guide the proposal distribution.
This is what the target distribution should look like¶
In [22]:
sigma = np.array([[1,0.8],[0.8,1]])
mu = np.zeros(2)
ys = np.random.multivariate_normal(mu, sigma, 1000)
sns.kdeplot(ys)
plt.axis([-3.5,3.5,-3.5,3.5])
pass

This is the HMC posterior¶
In [23]:
def E(A, u0, v0, u, v):
"""Total energy."""
return (u0 @ tau @ u0 + v0 @ v0) - (u @ tau@u + v @ v)
In [24]:
def leapfrog(A, u, v, h, N):
"""Leapfrog finite difference scheme."""
v = v - h/2 * A @ u
for i in range(N-1):
u = u + h * v
v = v - h * A @ u
u = u + h * v
v = v - h/2 * A @ u
return u, v
In [25]:
niter = 100
h = 0.01
N = 100
tau = la.inv(sigma)
orbit = np.zeros((niter+1, 2))
u = np.array([-3,3])
orbit[0] = u
for k in range(niter):
v0 = np.random.normal(0,1,2)
u, v = leapfrog(tau, u, v0, h, N)
# accept-reject
u0 = orbit[k]
a = np.exp(E(A, u0, v0, u, v))
r = np.random.rand()
if r < a:
orbit[k+1] = u
else:
orbit[k+1] = u0
In [26]:
sns.kdeplot(orbit)
plt.plot(orbit[:,0], orbit[:,1], alpha=0.2)
plt.scatter(orbit[:1,0], orbit[:1,1], c='red', s=30)
plt.scatter(orbit[1:,0], orbit[1:,1], c=np.arange(niter)[::-1], cmap='Reds')
plt.axis([-3.5,3.5,-3.5,3.5])
pass

In [ ]: