In [1]:
import os
import sys
import glob
import operator as op
import itertools as it
from functools import reduce, partial
import numpy as np
import pandas as pd
from pandas import DataFrame, Series
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context("notebook", font_scale=1.5)
%matplotlib inline
Homework 06¶
Write code to solve all problems. The grading rubric includes the following criteria:
- Correctness
- Readability
- Efficiency
Please do not copy answers found on the web or elsewhere as it will not benefit your learning. Searching the web for general references etc. is OK. Some discussion with friends is fine too - but again, do not just copy their answer.
Honor Code: By submitting this assignment, you certify that this is your original work.
Background for Exercises 1 and 2¶
The first 2 exercises are about using Newton’s method to find the cube roots of unity - find \(z\) such that \(z^3 = 1\). From the fundamental theorem of algebra, we know there must be exactly 3 complex roots since this is a degree 3 polynomial.
We start with Euler’s fabulous equation
Raising \(e^{ix}\) to the \(n\)th power where \(n\) is an integer, we get from Euler’s formula with \(nx\) substituting for \(x\)
Whenever \(nx\) is an integer multiple of \(2\pi\) (i.e. \(n=2\pi k\)), we have
So
So the cube roots of unity are \(1, e^{2\pi i/3}, e^{4\pi i/3}\).
While we can do this analytically, the idea is to use Newton’s method to find the basins of attraction for these roots, and in the process, discover some rather perplexing behavior of Newton’s method.
In [2]:
from sympy import Symbol, exp, I, pi, N, expand
from sympy import init_printing
init_printing()
In [3]:
expand(exp(2*pi*I/3), complex=True)
Out[3]:
In [4]:
expand(exp(4*pi*I/3), complex=True)
Out[4]:
In [5]:
plt.figure(figsize=(4,4))
roots = np.array([[1,0], [-0.5, np.sqrt(3)/2], [-0.5, -np.sqrt(3)/2]])
plt.scatter(roots[:,0], roots[:,1], s=50, c='red')
xp = np.linspace(0, 2*np.pi, 100)
plt.plot(np.cos(xp), np.sin(xp), c='blue');
Exercise 1 (20 points). Netwon’s method for functions of complex variables - stability and basins of attraction.
- Write a function with the following function signature
newton(z, f, fprime, max_iter=100, tol=1e-6)wherezis a starting value (a complex number e.g.3 + 4j)fis a function ofzfprimeis the derivative offThe function will run until either max_iter is reached or the absolute value of the Newton step is less than tol. In either case, the function should return the number of iterations taken and the final value ofzas a tuple (i,z).
- Define the function
fandfprimethat will result in Newton’s method finding the cube roots of 1. Find 3 starting points that will give different roots, and print both the start and end points.
In [6]:
def newton(z, f, fprime, max_iter=100, tol=1e-6):
"""The Newton-Raphson method."""
for i in range(max_iter):
step = f(z)/fprime(z)
if abs(step) < tol:
return i, z
z -= step
return i, z
In [7]:
f = lambda x: x**3 - 1
fprime = lambda x: 3*x**2
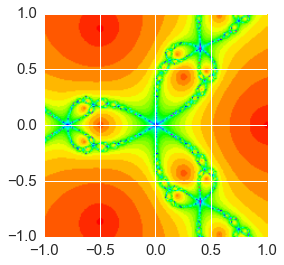
Exercise 2 (20 points). Write the following two plotting functions to see some (pretty) aspects of Newton’s algorithm in the complex plane.
- The first function
plot_newton_iters(f, fprime, n=200, extent=[-1,1,-1,1], cmap='hsv')calculates and stores the number of iterations taken for convergence (or max_iter) for each point in a 2D array. The 2D array limits are given byextent- for example, whenextent = [-1,1,-1,1]the corners of the plot are(-i, -i), (1, -i), (1, i), (-1, i). There arengrid points in both the real and imaginary axes. The argumentcmapspecifies the color map to use - the suggested defaults are fine. Finally plot the image usingplt.imshow- make sure the axis ticks are correctly scaled. Make a plot for the cube roots of 1. - The second function
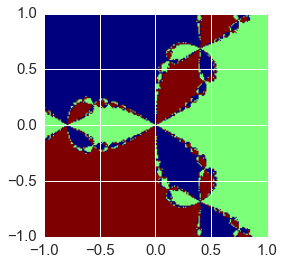
plot_newton_basins(f, fprime, n=200, extent=[-1,1,-1,1], cmap='jet')has the same arguments, but this time the grid stores the identity of the root that the starting point convered to. Make a plot for the cube roots of 1 - since there are 3 roots, there should be only 3 colors in the plot.
In [8]:
def plot_newton_iters(p, pprime, n=200, extent=[-1,1,-1,1], cmap='hsv'):
"""Shows how long it takes to converge to a root using the Newton-Rahphson method."""
m = np.zeros((n,n))
xmin, xmax, ymin, ymax = extent
for r, x in enumerate(np.linspace(xmin, xmax, n)):
for s, y in enumerate(np.linspace(ymin, ymax, n)):
z = x + y*1j
m[r, s] = newton(z, p, pprime)[0]
plt.imshow(m.T, cmap=cmap, extent=extent)
In [9]:
%%time
plot_newton_iters(f, fprime)
CPU times: user 1.23 s, sys: 3.41 ms, total: 1.23 s
Wall time: 1.23 s
In [10]:
def plot_newton_basins(p, pprime, n=200, extent=[-1,1,-1,1], cmap='jet'):
"""Shows basin of attraction for convergence to each root using the Newton-Raphson method."""
root_count = 0
roots = {}
m = np.zeros((n,n))
xmin, xmax, ymin, ymax = extent
for r, x in enumerate(np.linspace(xmin, xmax, n)):
for s, y in enumerate(np.linspace(ymin, ymax, n)):
z = x + y*1j
root = np.round(newton(z, p, pprime)[1], 1)
if not root in roots:
roots[root] = root_count
root_count += 1
m[r, s] = roots[root]
plt.imshow(m.T, cmap=cmap, extent=extent)
In [11]:
%%time
plot_newton_basins(f, fprime)
CPU times: user 2.05 s, sys: 3.56 ms, total: 2.05 s
Wall time: 2.05 s
Exercise 3 (30 points). Create your own steepest descent optimizer.
Your optimizer should take as arguments a function \(f\), its gradient, an initial guess, a step size, a tolerance (to determine convergence), and a maximum number of steps. It should output convergence status, total number of steps, and the value of the input variable that optimizes \(f\).
Setting \(\alpha = -0.05\), use your optimizer to find the minimum of
\[ \begin{align}\begin{aligned}f(x,y) = x^2 + 2y^2\\using an initial guess of :math:`(0.1,0.1)`, a tolerance of\end{aligned}\end{align} \]\(0.001\) and a max of \(100\) interations.
In this case, it is possible to (analytically) determine the optimal step size. Compute the optimal step size \(\alpha^*\) for the initial point of \((0.1,0.1)\) and run the optimizer using step sizes \(\alpha = \alpha^*/2\) and \(\alpha = 2\alpha^*\). What do you observe about the behavior of the optimizer as step size is varied?
In [12]:
def f(x):
return(x[0]**2 + 2*x[1]**2)
def gradf(x):
return(np.array([2*x[0],4*x[1]]))
def NCG(f,gradf,alpha,x0,tol=0.001,maxiter=100):
nsteps = 0
xs = [x0]
xnext=x0
while (nsteps<maxiter and abs(f(xnext))>tol ):
xnext = xs[nsteps] + alpha * gradf(xs[nsteps])
nsteps = nsteps+1
xs.append(xnext)
if (maxiter == nsteps):
converge = "Not Converged"
else:
converge = "Converged"
return(converge,nsteps,xs)
cnv, totsteps, listxs = NCG(f,gradf,-.05,np.array([0.1,0.1]))
print(f(listxs[totsteps]))
print(totsteps)
cnv, totsteps, listxs = NCG(f,gradf,-0.2777777,np.array([0.1,0.1]))
print(f(listxs[totsteps]))
print(totsteps)
cnv, totsteps, listxs = NCG(f,gradf,2*(-0.277777),np.array([0.1,0.1]))
print(f(listxs[totsteps]))
print(totsteps)
cnv, totsteps, listxs = NCG(f,gradf,(-0.277777)/2,np.array([0.1,0.1]))
print(f(listxs[totsteps]))
print(totsteps)
0.000892111760426
12
0.000370367407434
2
4.67078810442e+42
100
0.000905379424362
3
Exercise 4 (30 points). Conjugate Gradient.
Consider the function:
The following is intended to help you understand the conjugate gradient method, by computing the first two steps by hand (‘by hand’ means that you write code to explicitly compute each of the values requested).
- Express the function \(f\) in matrix form.
- Starting at some initial point \(x_0\in \mathbb{R}^2\), compute \(\alpha_0,p_0,x_1,\alpha_1,p_1\) and \(x_2\) as defined in the notes on Newton-CG.
Let \(v=(x,y)\)
\(f(v) = v^T A v + b v = v^T \left(\begin{matrix}1&0\\0&2\end{matrix}\right)v + \left(\begin{matrix}-2\\1\end{matrix}\right)v\)
\(p_0 = \nabla f = 2Av_0 + b = 2\left(\begin{matrix}1&0\\0&2\end{matrix}\right)v_0 + \left(\begin{matrix}-2\\1\end{matrix}\right)\)
\(\alpha_0 = -\frac{\langle{p}_0, {b}\rangle}{\,\,\,\|{p}_0\|_{A}^2} = -\frac{\langle{Av_0+b}, {b}\rangle}{\,\,\,\|{Av_0+b}\|_{A}^2}\), etc.
In [13]:
def get_alpha_p(A,v,b,oldp):
# gradient at current step
gradv = -A.dot(v) - b
# squared norm of previous p (in A-norm)
norm_oldp = oldp.dot(A.dot(oldp))
# next p is the current gradient, minus projection onto previous p
pnext = gradv - (oldp.dot(A.dot(gradv))/norm_oldp)*oldp
# squared A-norm of new p
norm_p = pnext.dot(A.dot(pnext))
# step size for this step
alpha = (pnext.dot(gradv))/(norm_p)
return ([pnext,alpha])
In [14]:
# Multiply matrix by factor of 2 - because of quadratic form
A = 2.0*np.array([[1,0],[0,2]])
print(A)
b = np.array([-2.0,1.0])
# Initial point
v0 = np.array([20,-20])
# Initial step = gradient
p0 = -A.dot(v0) - b
# Initial step size
#norm_p0 = p0.dot(A.dot(p0))
#alpha0 = -(p0.dot(b))/norm_p0
norm_p0 = np.dot(p0,np.dot(A,p0))
alpha0 = np.dot(p0,p0)/norm_p0
print("p0,alpha0")
print(p0,alpha0)
# Move to next point
v1 = v0 + alpha0*p0
print("v1")
print(v1)
# Get next step
p1,alpha1 = get_alpha_p(A,v1,b,p0)
print("p1,v1,alpha1")
print(p1,v1,alpha1)
# Move to third point
v2 = v1 + alpha1*p1
print(v2)
[[ 2. 0.]
[ 0. 4.]]
p0,alpha0
[-0.02 0.024] -20.618556701
v1
[ 1.42237113 -0.75084536]
p1,v1,alpha1
[ 0.61217983 0.25507493] [ 1.42237113 -0.75084536] 0.959895833333
[ 2.01 -0.506]
In [ ]: