|
Cryptology |
||||
|
Transposition Ciphers |
||||
The Turning Grille - "Apparatus for Cypher Correspondence" Patented #1163, 1875. Click on any image for an enlargement. (The letter "b" in the diagram simply represents a hinge.) The circular holes are cut out of the card. The message is written, one letter in each hole, until all the holes are filled. The card is then turned clockwise ninety degrees and the message is continued. The card may be turned four times to completely fill the 14 by 14 cell grid. Note the turning guide (the Roman numerals) in the lower right hand corner. |
||||
|
An Enigma Machine Simulator |
||||
 |
This fantastic simulator was written
by Dirk Rijmenants |
|||
Most substitution ciphers are simple additive shifts from a cleartext to a cryptotext alphabet. The shifts may change with each letter, group of letters or each message. |
||||
 |
A Centimeter Scale |
|||
 |
A "Slide Rule"
|
|||
 |
A "Cryptologic Slide Rule" |
|||
French
silver polyalphabetic substitution cipher disk by Nicolas Bion (1652-1733). |
||||
|
It seems likely that the progression served as a keying method: We could then repeat the key, but shifted, in the following manner: In a similar manner we could do the inverse, but it would not produce as irregular a key: Is this too complicated a procedure? Alberti suggested using a short key in the 1400s. The Rossignols were practised in cryptanalysis. By comparison, this procedure is relatively simple. |
|||
Evocrypt - A monoalphabetic substitution cipher cryptanalyzer |
||||
 |
XE6 EvoCrypt - Adaptation by Trey Bagley -021 April 2015 Lock in the second and third words as "we are." Lock "H" to "e" With those locked in, 100 runs of 500 generations will produce interesting results in a short time! |
|||
The Vernam Polyalphabetic Substitution Cipher using a One-Time-Key |
||||
ASCII / Decimal / Byte Conversions |
||||
 |
A Vernam Cipher (2012) utilizing all 94 printable ASCII characters Why usenumbers? The answer is relatively simple. Think of the addition as an offset on a slide rule, such as the linear slider rule above. The slide rule is simply a device to add logarithms, so it may easily be used to solve cryptograms as well. Texts must be entered in the white boxes using any of the printable ASCII characters, including numerals, spaces and punctuation (but no up or down arrows and no carraige-returns, tabs, or other control characters). Texts will remain gray until they are Entered into the converter, whereupon they will turn black. When text in any two boxes is Entered, text for the remaining box may be Extracted. The numeric values of the text characters (modified from ASCII) are shown in the gray box below. |
|||
Although this messages
looks like cleartext, it is, in fact, a cipher: |
A Vernam Cipher (2012) utilizing only lowercase ASCII letters
Texts must be entered in the white boxes using all lower-case letters and no spaces or punctuation. Texts will remain gray until they are Entered into the converter, whereupon they will turn black. When text in any two boxes is Entered, text for the remaining box may be Extracted. The numeric values of the text characters (a = 0 through z = 25) are shown in the gray box below. There is no reason why the entire ASCII character set may not be treated in this manner; however, for simplicity this application uses the old tradition of allowing for only lower-case letters and no white-space. |
|||
Only use bitmap (.bmp)
images. |
A Hybrid Steganographic Image Vernan
Cipher (unfinished) A Clear Image is included to demonstrate the embedding of Clear Test in an image without encipherment. This, of course, is a much less secure alternative |
|||
U.S. Army Cipher Device M-94 |
||||
|
Decipher this: |
U.S. Army Cipher Device M-94 AN EVOLUTIONARY DECRYPTION of a cyphertext might be found by modifying the Evolutionary Concert Tour application. The two systems are analogous: Finding the correct cleartext is a matter of finding the "fittest" (c.f. "shortest") arrangement of the 25 disks (c.f. "path through the 30 cities). The fitness of any disk order might be measured by the comparing the letter frequency of each line of text in that disk order to that of standard English. One might then choose the closest match as the fitness of that disk order. In this way we might be able to evolve a solution to the cyphertext. |
|||
Hiding Text in Images |
||||
|
Since the bitmap (.bmp) is the simplest uncompressed image file format, it should also be the simplest image format in which to hide text, making our programming efforts a little easier. Some drawbacks are that the file sizes are enormous and that bitmaps are not universally supported by Web browsers and Operating Systems. All works well with Windows and Internet Explorer, Chrome and Firefox. Clearly, the first step documented below is hardly hidden, but it does demonstrate a pixel interpretation of ASCII text. Not surprisingly, since ASCII characters range from 0-127, and the red, green and blue primaries range from 0-255, the colors of the ASCII characters are dark. So any image containing such a randomly dark texture is a dead give-away that there is text inside. We note that there is one piece of software offered for sale on the Web that hides text in images using a password. However, the image files grow by the size of the text and password added. Again, any image file that is substantially larger than it should be is a dead give-away that there is text hidden inside. |
||||
|
A Tribute to Herbert
O. Yardley This exhibit details the checkered career of Herbert O. Yardley (1889-1958), who headed the highly secret MI-8, or the "Black Chamber." Yardley began his career as a code clerk with the U.S. State Department, and during that service discovered his natural talent as a cryptanalyst. During World War I, Yardley served in the cryptologic section of Military Intelligence (MI) with the American Expeditionary Forces. After the war, Yardley lead the first peacetime cryptanalytic organization in the United States, MI-8. Funded by the Army and the State Department, MI-8, was disguised as a New York City company that made commercial codes for businesses. However, their actual mission was to break the diplomatic codes of different nations. A mission they were initially quite successful at completing, breaking codes from several foreign countries. MI-8 had an early success: in 1921-22, Yardley and his staff solved the cipher system used by Japanese negotiators at the Washington Naval Conference. They fed the decrypts to the U.S. chief negotiator, Charles Evans Hughes. The messages contained the Japaneses minimum demands at the conference. Hughes appeared to be outsmarting the Japanese to obtain a more favorable agreement on naval capital ships, when actually he was reading their negotiating position every day before he went into the bargaining sessions. In 1929, the State Department closed down MI-8. According to legend, Secretary of State Henry Stimson at that time spoke the famous sentence: Gentlemen do not read each others mail. Disappointed, unemployed, and accustomed to luxury, Yardley found himself in need of finances and in possession of his countrys secrets. He wrote The American Black Chamber, which revealed to the world the work of MI-8. It became an international best seller. Needless to say, the Army, which continued codebreaking, was not amused. And the Japanese, for their part, changed their code systems. Surprisingly, at the time, the wording of the espionage laws contained a loophole that prevented the government from prosecuting Yardley. Yardley, a brilliant cryptanalyst, as well as a promoter of the cryptologic cause, continued to provide expertise to various countries, but never again worked for the United States. |
Herbert O. Yardley A .jpg
image. |
 |
||
|
Herbert O. Yardley A .bmp
image. |
 |
|||
|
Herbert O. Yardley A .bmp
image with the text at left inserted at the bottom of the .bmp file using
SynEdit. The text appears at the top of the image as a somewhat random
texture. |
 |
|||
 |
An enlargement of the top of the image of Yardley showing the inserted text rendered as red, green and blue color triplets (pixels). | |||
|
|
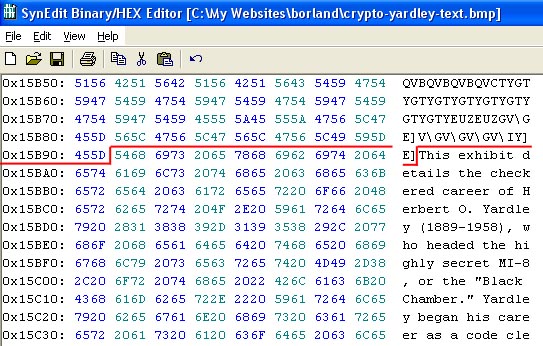
A portion of the bitmap (.bmp) image file with text inserted as seen in the binary/hexadecimal SynEdit editor. The division between true pixel triplets and ASCII text is delineated in red. |
|||
Let's dissect a six-by-six pixel bitmap image, shown here as a .jpg but actual size:
Let's blow up the six-by-six pixel image to 100 by 100 pixels so we can see it clearly: In Hex Editor, the hexadecimal code is shown in the left column, the ASCII equivalent (if there is any) in the right: Below is one annotation of the complete file as viewed in SynEdit's Hex Editor.
Below is another annotation of the complete file as viewed in SynEdit's Hex Editor:
|
Some resources for file formats: Wotsit's Format - The programmer's resource. Every file format in the world. ASCII, HEX, OCTAL and other charts and resources. |
|||
 @@
@@ 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}