
Text
(ASCII) data
Binary data
Counting bits and bytes
Text = a universal medium of data exchange
Text file formats
Economagic options
Text (ASCII) data. The raw material of statistical forecasting is data, and so to be a statistical forecaster you need to know a few things about how to dig up data and shovel it from one place to another. First, there are a couple of technical things you should know about how data is stored in the computer. There are two basic ways in which data may be electronically stored: "text" form or "binary" form. When data is stored in text form, it is stored as a sequence of characters in the computer's memory or on a disk. Thus, for example, the number 1.5 would be stored in text form as the character "1" followed by the character "." followed by the character "5".
Now, how does the computer actually store a character? The computer's physical memory consists of millions of transistors, each of which can be in an "off" or "on" state, and these two states can be used to represent the digits 0 and 1 in the binary numbering system. Thus, a single transistor stores a single binary digit, or bit, of data. (When data is transferred to a magnetic or optical disk, the "ons" and "offs" of the transistors are converted to patches of up-or-down magnetization on the magnetic medium or light-or-dark spots on the optical medium.) A group of 8 bits, called a byte, is the standard unit of information measurement in the computer. (In particular, file sizes and storage capacities are measured in bytes.) A byte of memory can hold an 8-digit binary number--i.e., an 8-digit sequence of 0's and 1's. There are 2^8=256 distinct combinations that you can make with 8 binary digits, so that in decimal terms a byte can store a number between 0 and 255. A byte therefore can also store one character out of an alphabet of up to 256 different characters, if each character is assigned to one of the numbers from 0 to 255.
A standard computer keyboard actually only has 96 printable characters (upper and lower case letters, punctuation marks, etc.) plus a few typewriter-control characters like "tab", "backspace", and "carriage return". Various other invisible device-control characters (originally used to control teletype machines) can be generated by holding down the "Ctrl" key while hitting other characters. Altogether, there are 96 printable characters and 32 control characters, for a total of 128 standard computer keyboard characters, and of these only about 100 correspond to visible symbols or typewriter keys. These 128 standard computer keyboard characters are assigned to the numbers between 0 and 127, and the printable characters are actually assigned to the numbers 32-127. The code according to which characters are assigned to these numbers is called ASCII (American Standard Code for Information Interchange). Under this code, decimal digits 0-9 are assigned to the numbers 48-57, upper case letters A-Z are assigned to the numbers 65-90, lower case letters a-z are assigned to the numbers 97-122, and various punctuation marks assigned to the remaining numbers between 32 and 127. (In some software that runs on MS-DOS PC's, the numbers greater than 127 are assigned to a variety of "extended" characters, including non-English characters.)
Data which is stored in the computer is considered to be "text data" if every byte contains one of the 100 or so codes for a "printable" or "typeable" standard character. Thus, text data is data that can be printed on the screen or a piece of paper as a string of familiar keyboard symbols, in which each symbol represents the contents of one byte of storage. Return to top of page.
Binary data. The alternative form of data storage is "binary" form. When numbers (or other pieces of information) are stored in binary form, the bit-patterns in bytes of storage do not necessarily correspond to the numeric codes for printable or typable characters--for example, they may correspond to arbitrary binary numbers less than 32 or greater than 127--and binary data therefore often looks like gobbledygook if you try to print it out or view it on the screen, because your video display or printer may respond perversely to some of the codes.
Internally the computer must ordinarily convert numbers to some kind of binary form in order to perform arithmetic. For example, a number such as 1.5 would normally be stored in (double-precision) binary floating point format, in which the number is first converted to scientific notation with around 15 decimal digits of precision, which in this case would look like 0.150000000000000E1. One byte of storage is then used to storage the integer exponent (here, the number 1) and seven bytes of storage are used to store the string of digits following the decimal point--and this is all done in binary (base-2) rather than decimal (base-10) form. Thus, 8 bytes of storage are typically used to store a number in binary floating point format, and all such numbers have the same number of significant digits of precision whether they are needed or not: the same number of bytes would be used to store 1.5 or 1.50000001 in binary floating point form. (Numbers often have only a few significant digits when they are first entered into the computer, but as soon as you begin to perform arithmetic with them, the number of digits that the computer keeps track of internally becomes important. For example, if you ask the computer to divide 1 by 3, it must store the result as 0.333333333333333--in binary form, of course!). Fifteen significant digits is normally sufficient for business purposes: it is roughly the number of digits needed to keep track of the U.S. national debt in dollars and cents.
Most computer programs maintain their own "native" files in some kind of binary form. For example, XLS (Excel spreadsheet) and SF* (Statgraphics file) are binary files, and so their contents cannot be directly printed out and they cannot always be shared between different programs. Even the DOC files produced by Word are, technically, binary files: they usually contain non-printable formatting codes as well as text. Executable program files (EXE and COM files) are another kind of binary file: the "source code" for a computer program is generally written and stored in text form, but the human-readable source code must be "compiled" into machine-readable binary form before it can be executed. Picture files ( BMP, GIF, and JPG files) and sound and video files (WAV and AVI files) are other examples of binary files. Return to top of page.
Picture and video data can be stored in "bitmap" (BMP) form, in which the color and brightness information for each pixel in a frame is stored as a numeric code in one or more bytes of memory, but more commonly such data is stored in some kind of "compressed" form in which redundant information is squeezed out. For example, if 100 consecutive pixels are blue, the code for "blue" is not stored 100 times: it is stored once for the first pixel, followed by a code signifying that the next 99 pixels are the same. GIF, JPG, and AVI files are examples of compressed files. Text data can also be compressed to economize on the representation of long strings of spaces or line-drawing characters that often occur in document files. When you ZIP a file, it is automatically compressed to some extent. Return to top of page.
Text = a universal medium of data exchange. As noted above, the term "text data" refers to data which has been literally copied from the printed page (or the typewriter keyboard) into the computer's memory, alloting one byte per character according to the ASCII coding scheme. In particular, when a number is stored as text data, it is literally recorded as a string of decimal digits and punctuation marks, exactly as it would have been entered at the keyboard or printed on the page. The precision you see is the precision you get: you would need 3 bytes of space to store the number 1.5 in text form, and you would need 10 bytes to store the number 1.50000001.
Text data is a universal medium for transferring information between different computer programs, because all computer programs that interact with humans must ultimately be able to read and write text. When you type at the keyboard, you are transmitting a stream of characters to the computer, and when you read a report on the screen or printer, you are reading a stream of characters spit out by the computer. Hence, no matter what the computer does with the data internally, it must be able to convert it to text form for input and output, and therefore different computer programs can always communicate with each other via text. Text files (that is, files which contain only text data) often have suggestive file name extensions such as TXT (text), PRN (print), ASC (ASCII), DAT (data), or CSV (comma-separated-value). Data which is provided by commercial data services or which is found on the internet is usually in some kind of text form, and all computer programs such as spreadsheets, word processors, database programs, and statistics programs have the capability to read and write text files, at least as an option. For example, when you use the "Save As" command to save a file to disk, you usually have the option to specify some kind of text format rather than using the program's "native" file format. Return to top of page.
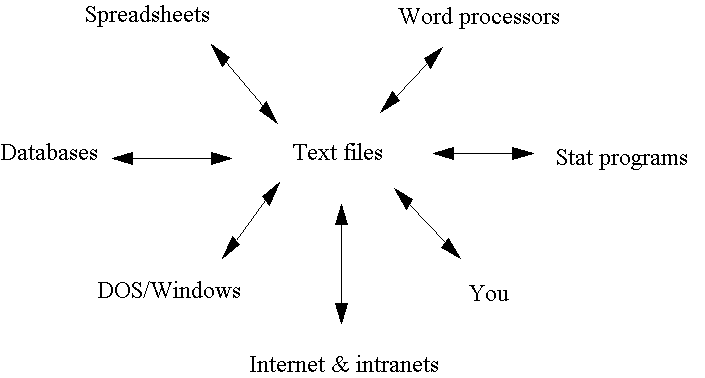
Text file formats. A file containing text data literally consists of a long stream of characters. When the data that is to be stored in a text file consists of rows and columns of numbers, it must be formatted in some way to indicate breaks between rows and columns. The methods of formatting that are most commonly used are derived from the keystroke commands that would normally be used to arrange data in tabular form on the page. For example, a new row of data is always indicated by a carriage-return character within the file. Within a row (i.e., within a single "line" of text in the file) numeric fields are usually separated ("delimited") by spaces, commas or "tab" characters. Thus, text files are usually classifed as space-delimited, comma-delimited, or tab-delimited according to which of these options is used. Another possibility is to use fixed format (sometimes called "Fortran format") in which each line contains exactly the same number of characters and is divided into numeric fields each of which has a fixed width. Thus, for example, each line in the file might consist of 80 characters representing 8 numeric fields each 10 characters in width, regardless of whether there are any spaces between the numbers.
As an example, consider a data file containing three observations of a date variable and two time series variables--i.e., two rows and three columns of data. It might look like this in space-delimited form:
1/1/85 102.5 44.1Inside the file, the character stream would actually look like this: <one> <slash> <one> <slash> <eight> <five> <space> <one> <zero> <two> <period> <five> <space> <four> <four> <period> <one> <return> <two> <slash> <one> ...etc., with each character corresponding to one byte of storage. (Here, <one> stands for a byte containing the ASCII code for the numeral 1, <slash> stands for a byte containing the ASCII code for the slash character, and so on.)
2/1/85 102.8 45.3
3/1/85 103.4 46.4
In comma-delimited format the same data would look like this:
1/1/85,102.5,44.1Sometimes fields that are to be processed as character data rather than numeric data are enclosed in quote marks. In our example, the date field might be treated as character data by the program writing the file, in which case it might be stored as follows:
2/1/85,102.8,45.3
3/1/85,103.4,46.4
"1/1/85",102.5,44.1In tab-delimited form, the same data might look like this when printed out or displayed on the screen:
"2/1/85",102.8,45.3
"3/1/85",103.4,46.4
1/1/85 102.5 44.1Of course, to the eye, a "tab" just looks like a bunch of spaces, but inside the file <tab> is a single character. The tab is an especially useful delimiter in situations where the file contains character data that may have embedded spaces, commas, or quote marks.
2/1/85 102.8 45.3
3/1/85 103.4 46.4
In fixed format, the same data could conceivably look like this:
01/01/85102.544.1(In the latter case, the program reading the file would presumably prompt you to tell it where to insert the breaks between different fields on the same line--i.e., you would need to specify that the "date" field was 8 characters wide, the first numeric field was 5 characters wide, and the second numeric field was 4 characters wide.)
02/01/85102.845.3
03/01/85103.446.4
If you are not sure exactly what kind of formatting has been used in a text file, you can always open the file in your word processor. (A word processor is a good all-purpose text editor.) If you view the file in your word processor in the "show formatting" mode (which displays visible symbols for spaces, tabs, and carriage-returns), you can determine exactly how the data fields have been delimited.
