C Crash Course¶
C functions are typically split into header files (.h) where things
are declared but not defined, and implementation files (.c) where
they are defined. When we run the C compiler, a complex sequence of
events is triggered with the usual successful outcome begin an
executable file as illustrated at http://www.codingunit.com/
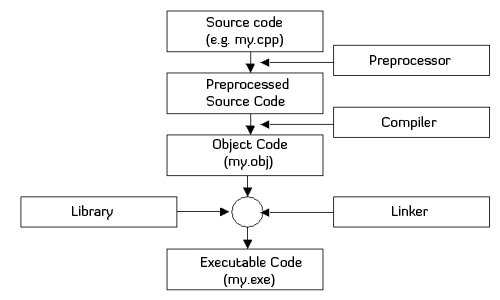
Compilation process
The preprocessor merges the contents of the header and implementation
files, and also expands any macros. The compiler then translates these
into low level object code (.o) for each file, and the linker then
joins together the newly generated object code with pre-compiled object
code from libraries to form an executable. Sometimes we just want to
generate object code and save it as a library (e.g. so that we can use
it in Python).
In [2]:
from IPython.display import Image
A tutorial example - coding a Fibonacci function in C¶
Python version¶
In [3]:
def fib(n):
a, b = 0, 1
for i in range(n):
a, b = a+b, a
return a
In [4]:
fib(100)
Out[4]:
354224848179261915075
C version¶
Implemetnation file¶
In [6]:
%%file fib.c
double fib(int n) {
double a = 0, b = 1;
for (int i=0; i<n; i++) {
double tmp = b;
b = a;
a += tmp;
}
return a;
}
Writing fib.c
Driver program¶
In [7]:
%%file main.c
#include <stdio.h> // for printf()
#include <stdlib.h> // for atoi())
#include "fib.h" // for fib()
int main(int argc, char* argv[]) {
int n = atoi(argv[1]);
printf("%f", fib(n));
}
Writing main.c
Makefile¶
In [8]:
%%file Makefile
CC=clang
CFLAGS=-Wall
fib: main.o fib.o
$(CC) $(CFLAGS) -o fib main.o fib.o
main.o: main.c fib.h
$(CC) $(CFAGS) -c main.c
fib.o: fib.c
$(CC) $(CFLAGS) -c fib.c
clean:
rm -f *.o
Overwriting Makefile
C Basics¶
The basic types are very simple - use int, float and double for numbers. In general, avoid float for plain C code as its lack of precision may bite you unless you are writing CUDA code. Strings are quite nasty to use in C - I would suggest doing all your string processing in Python ...
Structs are sort of like classes in Python
struct point {
double x;
double y;
double z;
};
struct point p1 = {.x = 1, .y = 2, .z = 3};
struct point p2 = {1, 2, 3};
struct point p3;
p3.x = 1;
p3.y = 2;
p3.z = 3;
You can define your own types using typedef -.e.g.
#include <stdio.h>
struct point {
double x;
double y;
double z;
};
typedef struct point point;
int main() {
point p = {1, 2, 3};
printf("%.2f, %.2f, %.2f", p.x, p.y, p.z);
};
Most of the operators in C are the same in Python, but an important difference is the increment/decrement operator. That is
int c = 10;
c++; // same as c = c + 1, i.e., c is now 11
c--; // same as c = c - 1, i.e.. c is now 10 again
There are two forms of the increment operator - postfix c++ and
prefix ++c. Both increment the variable, but in an expression, the
postfix version returns the value before the increment and the prefix
returns the value after the increment.
In [11]:
%%file increment.c
#include <stdio.h>
#include <stdlib.h>
int main()
{
int x = 3, y;
y = x++; // x is incremented and y takes the value of x before incrementation
printf("x = %d, y = %d\n", x, y);
y = ++x; // x is incremented and y takes the value of x after incrementation
printf("x = %d, y = %d\n", x, y);
}
Writing increment.c
In [12]:
%%bash
clang -Wall increment.c -o increment
./increment
x = 4, y = 3
x = 5, y = 5
Ternary operator¶
The ternary operator expr = condition ? expr1 : expr2 allows an
if-else statement to be put in a single line. In English, this says that
if condition is True, expr1 is assigned to expr, otherwise expr2 is
assigned to expr. We used it in the tutorial code to print a comma
between elements in a list unless the element was the last one, in which
case we printed a new line ‘:raw-latex:`\n`‘.
Note: There is a similar ternary construct in Python
expr = expr1 if condition else epxr2.
Very similar to Python or R. The examples below should be self-explanatory.
if-else¶
// Interpretation of grades by Asian parent
if (grade == 'A') {
printf("Acceptable\n");
} else if (grade == 'B') {
printf("Bad\n");
} else if (grade == 'C') {
printf("Catastrophe\n");
} else if (grade == 'D') {
printf("Disowned\n");
} else {
printf("Missing child report filed with local police\n")
}
for, while, do¶
// Looping variants
// the for loop in C consists of the keyword if followed
// (initializing statement; loop condition statement; loop update statement)
// followed by the body of the loop in curly braces
int arr[3] = {1, 2, 3};
for (int i=0; i<sizeof(arr)/sizeof(arr[0]); i++) {
printf("%d\n", i);
}
int i = 3;
while (i > 0) {
i--;
}
int i = 3;
do {
i==;
} while (i > 0);
Automatic arrays¶
If you know the size of the arrays at initialization (i.e. when the program is first run), you can usually get away with the use of fixed size arrays for which C will automatically manage memory for you.
int len = 3;
// Giving an explicit size
double xs[len];
for (int i=0; i<len; i++) {
xs[i] = 0.0;
}
// C can infer size if initializer is given
double ys[] = {1, 2, 3};
Pointers and dynamic memory management¶
Otherwise, we have to manage memory ourselves using pointers. Basically, memory in C can be automatic, static or dynamic. Variables in automatic memory are managed by the computer, when it goes out of scope, the variable disappears. Static variables essentially live forever. Dynamic memory is allocated in the stack, and you manage its lifetime.
Mini-glossary: * scope: Where a variable is visible - basically C variables have block scope - variables either live within a pair of curly braces (including variables in parentheses just before block such as function arguments and the counter in a for loop), or they are visible throughout the file. * stack: Computer memory is divided into a stack (small) and a heap (big). Automatic variables are put on the stack; dynamic variables are put in the heap. Hence if you have a very large array, you would use dynamic memory allocation even if you know its size at initialization.
Any variable in memory has an address represented as a 64-bit integer in
most operating systems. A pointer is basically an integer containing the
address of a block of memory. This is what is returned by functions such
as malloc. In C, a pointer is denoted by ‘*’. However, the ‘*’
notation is confusing because its interpretation depends on whenever you
are using it in a declaration or not. In a declaration
int *p = malloc(sizeof(int)); // p is a pointer to an integer
*p = 5; // *p is an integer
To get the actual address value, we can use the & address operator.
This is often used so that a function can alter the value of an argument
passed in (e.g. see address.c below).
In [13]:
%%file pointers.c
#include <stdio.h>
int main()
{
int i = 2;
int j = 3;
int *p;
int *q;
*p = i;
q = &j;
printf("p = %p\n", p);
printf("*p = %d\n", *p);
printf("&p = %p\n", &p);
printf("q = %p\n", q);
printf("*q = %d\n", *q);
printf("&q = %p\n", &q);
}
Writing pointers.c
In [14]:
%%bash
clang -Wall -Wno-uninitialized pointers.c -o pointers
./pointers
p = 0x7fff55d34898
*p = 2
&p = 0x7fff55d34870
q = 0x7fff55d34878
*q = 3
&q = 0x7fff55d34868
In [15]:
%%file address.c
#include <stdio.h>
void change_arg(int *p) {
*p *= 2;
}
int main()
{
int x = 5;
change_arg(&x);
printf("%d\n", x);
}
Writing address.c
In [16]:
%%bash
clang -Wall address.c -o address
./address
10
If we want to store a whole sequence of ints, we can do so by simply allocating more memory:
int *ps = malloc(5 * sizeof(int)); // ps is a pointer to an integer
for (int i=0; i<5; i++) {
ps[i] = i;
}
The computer will find enough space in the heap to store 5 consecutive
integers in a contiguous way. Since C arrays are all fo the same
type, this allows us to do pointer arithmetic - i.e. the pointer
ps is the same as &ps[0] and ps + 2 is the same as
&ps[2]. An example at this point is helpful.
In [17]:
%%file pointers2.c
#include <stdio.h>
#include <stdlib.h>
int main()
{
int *ps = malloc(5 * sizeof(int));
for (int i =0; i < 5; i++) {
ps[i] = i + 10;
}
printf("%d, %d\n", *ps, ps[0]); // remmeber that *ptr is just a regular variable outside of a declaration, in this case, an int
printf("%d, %d\n", *(ps+2), ps[2]);
printf("%d, %d\n", *(ps+4), *(&ps[4])); // * and & are inverses
}
Writing pointers2.c
In [18]:
%%bash
clang -Wall pointers2.c -o pointers2
./pointers2
10, 10
12, 12
14, 14
Pointers and arrays¶
An array name is actually just a constant pointer to the address of the beginning of the array. Hence, we can dereference an array name just like a pointer. We can also do pointer arithmetic with array names - this leads to the following legal but weird syntax:
arr[i] = *(arr + i) = i[arr]
In [19]:
%%file array_pointer.c
#include <stdio.h>
int main()
{
int arr[] = {1, 2, 3};
printf("%d\t%d\t%d\t%d\t%d\t%d\n", *arr, arr[0], 0[arr], *(arr + 2), arr[2], 2[arr]);
}
Writing array_pointer.c
In [20]:
%%bash
clang -Wall array_pointer.c -o array_pointer
./array_pointer
1 1 1 3 3 3
More on pointers¶
Different kinds of nothing: There is a special null pointer
indicated by the keyword NULL that points to nothing. It is typically
used for pointer comparisons, since NULL pointers are guaranteed to
compare as not equal to any other pointer (including another NULL). In
particular, it is often used as a sentinel value to mark the end of a
list. In contrast a void pointer (void *) points to a memory location
whose type is not declared. It is used in C for generic operations - for
example, malloc returns a void pointer. To totally confuse the
beginning C student, there is also the NUL keyword, which refers to the
'\0' character used to terminate C strings. NUL and NULL are totally
different beasts.
Deciphering pointer idioms: A common C idiom that you should get
used to is *q++ = *p++ where p and q are both pointers. In English,
this says
- *q = *p (copy the variable pointed to by p into the variable pointed to by q)
- increment q
- increment p
In [21]:
%%file pointers3.c
#include <stdio.h>
#include <stdlib.h>
int main()
{
// example 1
typedef char* string;
char *s[] = {"mary ", "had ", "a ", "little ", "lamb", NULL};
for (char **sp = s; *sp != NULL; sp++) {
printf("%s", *sp);
}
printf("\n");
// example 2
char *src = "abcde";
char *dest = malloc(5); // char is always 1 byte by C99 definition
char *p = src + 4;
char *q = dest;
while ((*q++ = *p--)); // put the string in src into dest in reverse order
for (int i = 0; i < 5; i++) {
printf("i = %d, src[i] = %c, dest[i] = %c\n", i, src[i], dest[i]);
}
}
Writing pointers3.c
In [22]:
%%bash
clang -Wall pointers3.c -o pointers3
./pointers3
mary had a little lamb
i = 0, src[i] = a, dest[i] = e
i = 1, src[i] = b, dest[i] = d
i = 2, src[i] = c, dest[i] = c
i = 3, src[i] = d, dest[i] = b
i = 4, src[i] = e, dest[i] = a
pointers3.c:7:19: warning: unused typedef 'string' [-Wunused-local-typedef]
typedef char* string;
^
1 warning generated.
In [23]:
%%file square.c
#include <stdio.h>
double square(double x)
{
return x * x;
}
int main()
{
double a = 3;
printf("%f\n", square(a));
}
Writing square.c
In [24]:
%%bash
clang -Wall square.c -o square
./square
9.000000
How to make a nice function pointer: Start with a regular function declaration func, for example, here func is a function that takes a pair of ints and returns an int
int func(int, int);
To turn it to a function pointer, just add a * and wrap in
parenthesis like so
int (*func)(int, int);
Now func is a pointer to a function that takes a pair of ints and
returns an int. Finally, add a typedef so that we can use func as a
new type
typedef int (*func)(int, int);
which allows us to create arrays of function pointers, higher order functions etc as shown in the following example.
In [25]:
%%file square2.c
#include <stdio.h>
#include <math.h>
// Create a function pointer type that takes a double and returns a double
typedef double (*func)(double x);
// A higher order function that takes just such a function pointer
double apply(func f, double x)
{
return f(x);
}
double square(double x)
{
return x * x;
}
double cube(double x)
{
return pow(x, 3);
}
int main()
{
double a = 3;
func fs[] = {square, cube, NULL};
for (func *f=fs; *f; f++) {
printf("%.1f\n", apply(*f, a));
}
}
Writing square2.c
In [26]:
%%bash
clang -Wall -lm square2.c -o square2
./square2
9.0
27.0
As you have seen, the process of C program compilation can be quite
messy, with all sorts of different compiler and linker flags to specify,
libraries to add and so on. For this reason, most C programs are
compiled using the make built tool that you are already familiar
with. Here is a simple generic makefile that you can customize to
compile your own programs adapted from the book 21st Century C by Ben
Kelmens (O’Reilly Media).
- TARGET: Typically the name of the executable
- OBJECTS: The intermediate object files - typically there is one file.o for every file.c
- CFLAGS: Compiler flags, e.g. -Wall (show all warnings), -g (add debug information), -O3 (use level 3 optimization). Also used to indicate paths to headers in non-standard locations, e.g. -I/opt/include
- LDFLAGS: Linker flags, e.g. -lm (link against the libmath library). Also used to indicate path to libraries in non-standard locations, e.g. -L/opt/lib
- CC: Compiler, e.g. gcc or clang or icc
In addition, there are traditional dummy flags * all: Builds all targets (for example, you may also have html and pdf targets that are optional) * clean: Remove intermediate and final products generated by the makefile
In [27]:
%%file makefile
TARGET =
OBJECTS =
CFLAGS = -g -Wall -O3
LDLIBS =
CC = c99
all: TARGET
clean:
rm $(TARGET) $(OBJECTS)
$(TARGET): $(OBJECTS)
Overwriting makefile
Just fill in the blanks with whatever is appropriate for your program.
Here is a simple example where the main file test_main.c uses a
function from stuff.c with declarations in stuff.h and also
depends on the libm C math library.
In [28]:
%%file stuff.h
#include <stdio.h>
#include <math.h>
void do_stuff();
Writing stuff.h
In [29]:
%%file stuff.c
#include "stuff.h"
void do_stuff() {
printf("The square root of 2 is %.2f\n", sqrt(2));
}
Writing stuff.c
In [30]:
%%file test_make.c
#include "stuff.h"
int main()
{
do_stuff();
}
Writing test_make.c
In [31]:
%%file makefile
TARGET = test_make
OBJECTS = stuff.o
CFLAGS = -g -Wall -O3
LDLIBS = -lm
CC = clang
all: $(TARGET)
clean:
rm $(TARGET) $(OBJECTS)
$(TARGET): $(OBJECTS)
Overwriting makefile
In [32]:
! make
clang -g -Wall -O3 -c -o stuff.o stuff.c
clang -g -Wall -O3 test_make.c stuff.o -lm -o test_make
In [33]:
! ./test_make
The square root of 2 is 1.41
In [34]:
# Make is clever enough to recompile only what has been changed since the last time it was called
! make
make: Nothing to be done for `all'.
In [35]:
! make clean
rm test_make stuff.o
In [36]:
! make
clang -g -Wall -O3 -c -o stuff.o stuff.c
clang -g -Wall -O3 test_make.c stuff.o -lm -o test_make
Try to fix the following buggy program.
In [37]:
%%file buggy.c
# Create a function pointer type that takes a double and returns a double
double *func(double x);
# A higher order function that takes just such a function pointer
double apply(func f, double x)
{
return f(x);
}
double square(double x)
{
return x * x;
}
double cube(double x)
{
return pow(3, x);
}
double mystery(double x)
{
double y = 10;
if (x < 10)
x = square(x);
else
x += y;
x = cube(x);
return x;
}
int main()
{
double a = 3;
func fs[] = {square, cube, mystery, NULL}
for (func *f=fs, f != NULL, f++) {
printf("%d\n", apply(f, a));
}
}
Writing buggy.c
In [38]:
! clang -g -Wall buggy.c -o buggy
buggy.c:2:3: error: invalid preprocessing directive
# Create a function pointer type that takes a double and returns a double
^
buggy.c:5:3: error: invalid preprocessing directive
# A higher order function that takes just such a function pointer
^
buggy.c:6:14: error: unknown type name 'func'
double apply(func f, double x)
^
buggy.c:18:12: warning: implicitly declaring library function 'pow' with type
'double (double, double)'
return pow(3, x);
^
buggy.c:18:12: note: include the header <math.h> or explicitly provide a
declaration for 'pow'
buggy.c:35:9: error: expected ';' after expression
func fs[] = {square, cube, mystery, NULL}
^
;
buggy.c:35:10: error: use of undeclared identifier 'fs'
func fs[] = {square, cube, mystery, NULL}
^
buggy.c:35:13: error: expected expression
func fs[] = {square, cube, mystery, NULL}
^
buggy.c:35:17: error: expected expression
func fs[] = {square, cube, mystery, NULL}
^
buggy.c:35:5: warning: expression result unused [-Wunused-value]
func fs[] = {square, cube, mystery, NULL}
^~~~
2 warnings and 7 errors generated.
What other language has an annual Obfuscated Code Contest http://www.ioccc.org/? In particular, the following features of C are very conducive to writing unreadable code:
- lax rules for identifiers (e.g. _o, _0, _O, O are all valid identifiers)
- chars are bytes and pointers are integers
- pointer arithmetic means that
array[index]is the same as*(array+index)which is the same asindex[array]! - lax formatting rules especially with respect to whitespace (or lack of it)
- Use of the comma operator to combine multiple expressions together with the ?: operator
- Recursive function calls - e.g. main calling main repeatedly is legal C
Here is one winning entry from the 2013 IOCCC entry that should warm the heart of statisticians - it displays sparklines (invented by Tufte).
main(a,b)char**b;{int c=1,d=c,e=a-d;for(;e;e--)_(e)<_(c)?c=e:_(e)>_(d)?d=e:7;
while(++e<a)printf("\xe2\x96%c",129+(**b=8*(_(e)-_(c))/(_(d)-_(c))));}
In [39]:
%%file sparkl.c
main(a,b)char**b;{int c=1,d=c,e=a-d;for(;e;e--)_(e)<_(c)?c=e:_(e)>_(d)?d=e:7;
while(++e<a)printf("\xe2\x96%c",129+(**b=8*(_(e)-_(c))/(_(d)-_(c))));}
Writing sparkl.c
In [40]:
! gcc -Wno-implicit-int -include stdio.h -include stdlib.h -D'_(x)=strtof(b[x],0)' sparkl.c -o sparkl
In [42]:
import numpy as np
np.set_printoptions(linewidth=np.infty)
print(' '.join(map(str, (100*np.sin(np.linspace(0, 8*np.pi, 30))).astype('int'))))
0 76 98 51 -31 -92 -88 -21 60 99 68 -10 -82 -96 -41 41 96 82 10 -68 -99 -60 21 88 92 31 -51 -98 -76 0
In [43]:
%%bash
./sparkl 0 76 98 51 -31 -92 -88 -21 60 99 68 -10 -82 -96 -41 41 96 82 10 -68 -99 -60 21 88 92 31 -51 -98 -76 0
▅██▇▃▁▁▄▇▉▇▄▁▁▃▆██▅▂▁▂▅██▆▂▁▁▅
If you have too much time on your hands and really want to know how not to write C code (unless you are crafting an entry for the IOCCC), I recommend this tutorial http://www.dreamincode.net/forums/topic/38102-obfuscated-code-a-simple-introduction/
In [ ]: