 How to choose forecasting models
How to choose forecasting models
Steps in
choosing a forecasting model
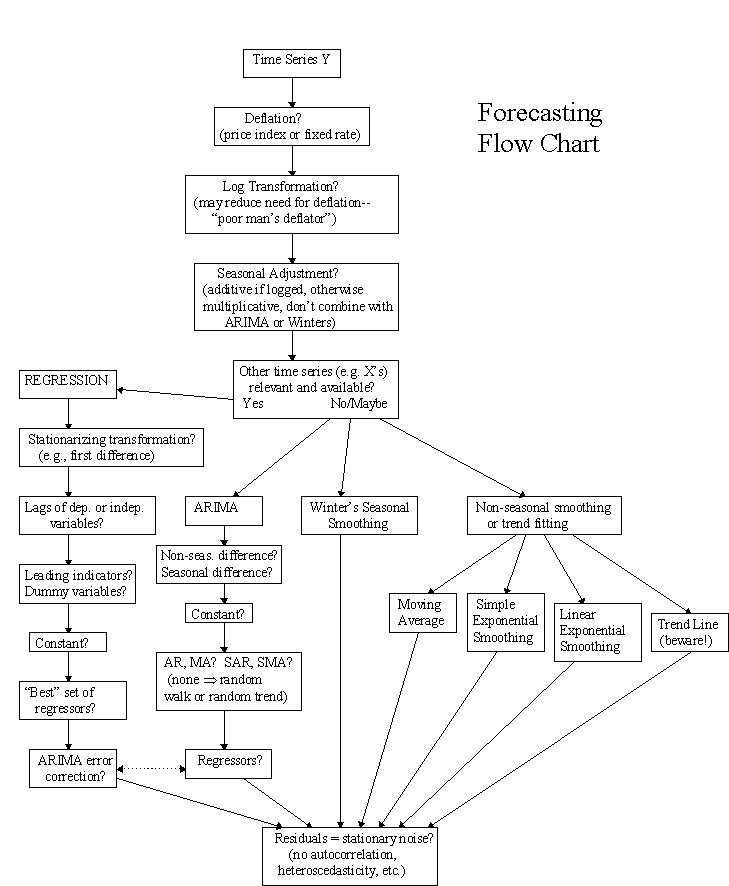
Forecasting flow chart
Data transformations and forecasting models: what to use
and when
Automatic forecasting software
Political and ethical issues in forecasting
How to avoid trouble: principles of good data analysis
{kind=link}
How to avoid trouble:
principles of good data analysis
- Do some background research
before running any numbers. Be
sure you understand the objective, the theory, the jargon, and the
conventional wisdom. Ask others what they
know about the problem. Do more of the same web-searching that
brought you to this site, and be critical of everything you find.
- Be thorough in your search for
data. In the end, your
forecasts will contain no information that is not hidden in it
somewhere. In some cases (say,
designed experiments) the data may be limited in scope and already in
hand, but in many cases it will be up to you to identify and collect it,
and this may the most important and time-consuming part of the
project. We now live in the
era of "megadata",
but often the data that you need
is not so easy to find.
- Check the data carefully once
you have it: make sure you
know where the numbers came from, what they mean, how they were measured,
how they are aligned in time, and whether they are accurate. A lot of
cleaning and merging of data may be needed before any analysis can begin,
and you should know how to do it. You may find that you need yet-more-data
or better-quality data to answer the key questions, and sometimes the most
useful lesson is that the organization will need to do a better job of
managing its data in the future.
- Use descriptive,
self-explanatory names for your variables (not Y’s and X’s or
cryptological character strings) so that their meaning and units are clear
and so that your computer output is self-documenting to the greatest
extent possible.
- Once you begin your analysis,
follow good modeling practices:
perform exploratory data analysis, use appropriate model types,
interpret their estimated parameters, check their residual diagnostics,
question their assumptions, and validate them with out-of-sample testing
where possible.
- Make effective use of
statistical graphics in your own analysis and in your presentation of your
results to others, and follow rules of good graphics. Among other things: graphs should
be self-explanatory and not contain visual puzzles, they should have
titles that are specific to the variables and models, axes should be well-scaled
and well-labeled, the data area should have a white background, grid lines
(if any are needed) should not be too dark, point and line widths should be
sized appropriately for the density of the data, self-promoting artwork
(3-D perspective, etc.) should be avoided, and above all, the data should
tell its own story.
- Keep in mind that not all
relationships are linear and additive, not all randomness is normally
distributed, and regression models are not magic boxes that can predict
anything from anything. Be
aware that it may be necessary to transform some of your variables
(through deflating, logging, differencing, etc.) in order to match their
patterns up with each other in the way that linear models require.
- When comparing models, focus on
the right objectives, which are usually making the smallest possible
errors in the future and
deriving inferences that are genuinely useful
for decision making. A good
fit to past data does not always guarantee an equally good prediction of
what will happen next, and statistical significance is not always
the same as practical significance.
- Other things being equal, KEEP
IT SIMPLE and intuitively reasonable. If others don’t understand the
model, they may not use it, and perhaps they shouldn’t: simple
models often
outperform complicated models in practice.
- If you use automatic
forecasting software, you are
still responsible for the model that is chosen, and you should be able to
explain its logic to others. The availability of such software
does not make it unnecessary to know how the models work. Rather, it makes that knowledge
even more important. (By
reading what is on this site, you have become partly qualified.) Be aware
that in automatic rankings of models, there may be only tiny differences
in error stats between the winner and its near competitors, and you may
need to take other factors into account in your final selection, such as
simplicity, clarity, and intuition. And again, your software cannot make something out of nothing.
If your data is not informative or not properly organized to begin with, automatic methods will not turn it into gold.
- Leave a paper trail, i.e., keep
well-annotated records of your model-fitting efforts. Don’t
just save your computer files:
write up notes as you go along. Someone else (who may be a
sharp-penciled auditor or perhaps only yourself 12 months hence) may need to
reconstruct what you did and why you did it. Intelligent naming of
variables and labeling of tables and charts will make this easier.
- Neither overstate nor
understate the accuracy of your forecast, and do not merely give a point
value. Always report standard errors and/or confidence intervals.
- If different forecasting
approaches lead to different results, focus on differences in their
underlying assumptions, their sources of data, their intrinsic biases, and
their respective margins for error.
Don’t just argue over the outputs. Look for opportunities to combine
independent viewpoints and information.
- After all has been said, if you
believe your model is more useful and better supported than the
alternatives, stand up for it.
The future may still be very uncertain, but decisions ought to be
based on the best understanding of that uncertainty. If you don't have
confidence in your model (or anyone else’s), admit it, and keep
digging.
- Thank
you!