from __future__ import division
import os
import sys
import glob
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
%matplotlib inline
%precision 4
plt.style.use('ggplot')
from IPython.display import HTML, Image
Writing CUDA in C¶
Review of GPU Architechture - A Simplification¶
Memory¶
GPUs or GPGPUs are complex devices, but to get started, one really just needs to understand a more simplistic view.
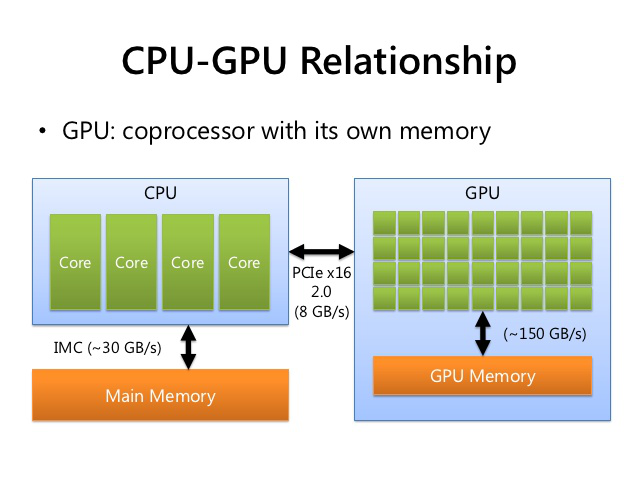
GPUs and CPUs
The most important thing to understand about memory, is that the CPU can access both main memory (host) and GPU memory (device). The device sees only its memory, and cannot access the host memory.
Kernels, Threads and Blocks¶
Recall that GPUs are SIMD. This means that each CUDA core gets the same code, called a ‘kernel’. Kernels are programmed to execute one ‘thread’ (execution unit or task). The ‘trick’ is that each thread ‘knows’ its identity, in the form of a grid location, and is usually coded to access an array of data at a unique location for the thread.
We will concentrate on a 1-dimensional grid with each thread in a block by itself, but let’s understand when we might want to organize threads into blocks.
GPU memory can be expanded (roughly) into 3 types:
- local - memory only seen by the thread. This is the fastest type
- shared - memory that may be seen by all threads in a block. Fast memory, but not as fast as local.
- global - memory seen by all threads in all blocks. This is the slowest to access.
So, if multiple threads need to use the same data (not unique chunks of an array, but the very same data), then those threads should be grouped into a common block, and the data should be stored in shared memory.
Cuda C program - an Outline¶
The following are the minimal ingredients for a Cuda C program:
- The kernel. This is the function that will be executed in parallel on the GPU.
- Main C program
- allocates memory on the GPU
- copies data in CPU memory to GPU memory
- ‘launches’ the kernel (just a function call with some extra arguments)
- copies data from GPU memory back to CPU memory
Kernel Code¶
%%file kernel.hold
__global void square_kernel(float *d_out, float *d_in){
int i = thread.Idx; # This is a unique identifier of the thread
float f = d_in[i] # Why this statement?
d_out[i] = f*f; # d_out is what we will copy back to the host memory
}
Overwriting kernel.hold
CPU Code¶
%%file main.hold
int main(int argc, char **argv){
const int ARRAY_SIZE = 64;
const int ARRAY_BYTES = ARRAY_SIZE * sizeof(float);
float h_in[ARRAY_SIZE];
for (int i =0;i<ARRAY_SIZE;i++){
h_in[i] = float(i);
} float h_out[ARRAY_SIZE];
float *d_in; // These are device memory pointers
float *d_out;
cudaMalloc((void **) &d_in, ARRAY_BYTES);
cudaMalloc((void **) &d_out, ARRAY_BYTES);
cudaMemcpy(d_in, h_in, ARRAY_BYTES,cudaMemcpyHostToDevice);
square_kernel<<<1,ARRAY_SIZE>>>(d_out,d_in);
cudaMemcpy(h_out,d_out,ARRAY_BYTES,cudaMemcpyDeviceToHost);
for (int i = 0;i<ARRAY_SIZE;i++){
printf("%f", h_out[i]);
printf(((i % 4) != 3 ? "\t" : "\n"));
}
cudaFree(d_in);
}
Overwriting main.hold