SQL Queries 02¶
[1]:
import pandas as pd
[2]:
import numpy as np
[3]:
%load_ext sql
[4]:
%sql sqlite://
Create toy data set¶
[5]:
from faker import Faker
[6]:
fake = Faker()
[7]:
names = list(set([fake.name() for i in range(100)]))
[8]:
np.random.seed(123)
n1 = 30
bios821 = pd.DataFrame(dict(
name=np.random.choice(names, n1, replace=False),
grade=np.random.randint(50, 101, n1)))
n2 = 30
bios823 = pd.DataFrame(dict(
name=np.random.choice(names, n2, replace=False),
grade=np.random.randint(50, 101, n2)))
[9]:
%%sql
DROP TABLE IF EXISTS bios821;
DROP TABLE IF EXISTs bios823
* sqlite://
Done.
Done.
[9]:
[]
[10]:
%sql -p bios821
* sqlite://
[10]:
'Persisted bios821'
[11]:
%sql -p bios823
* sqlite://
[11]:
'Persisted bios823'
[12]:
%sql SELECT * FROM bios821 LIMIT 3
* sqlite://
Done.
[12]:
| index | name | grade |
|---|---|---|
| 0 | Mrs. Michele Ingram | 65 |
| 1 | Mark Shaffer | 90 |
| 2 | Alexandra James | 75 |
[13]:
%sql SELECT * FROM bios823 LIMIT 3
* sqlite://
Done.
[13]:
| index | name | grade |
|---|---|---|
| 0 | Loretta Smith | 59 |
| 1 | Allison Kirby | 90 |
| 2 | Robert Wong | 91 |
Subqueries¶
There are 3 ways to use a sub-query:
with
inwith
existswith a comparison operator
1. What students take both bios821 and bios823?
Using set operations.¶
[14]:
%%sql
SELECT name FROM bios821
INTERSECT
SELECT name FROM bios823
* sqlite://
Done.
[14]:
| name |
|---|
| Alexandra James |
| Cindy Clark |
| Dr. Scott Mendoza MD |
| Jennifer Hunt |
| Kathy Cochran |
| Nancy Castaneda |
| Robert Wong |
| Sharon Porter |
Using EQUIJOIN.¶
[15]:
%%sql
SELECT DISTINCT bios821.name
FROM bios821, bios823
WHERE bios821.name = bios823.name
* sqlite://
Done.
[15]:
| name |
|---|
| Alexandra James |
| Nancy Castaneda |
| Jennifer Hunt |
| Dr. Scott Mendoza MD |
| Kathy Cochran |
| Cindy Clark |
| Robert Wong |
| Sharon Porter |
Using sub-query.¶
[16]:
%%sql
SELECT DISTINCT name FROM bios821
WHERE name IN (
SELECT name FROM bios823
)
* sqlite://
Done.
[16]:
| name |
|---|
| Alexandra James |
| Nancy Castaneda |
| Jennifer Hunt |
| Dr. Scott Mendoza MD |
| Kathy Cochran |
| Cindy Clark |
| Robert Wong |
| Sharon Porter |
Using a view.¶
[19]:
%%sql
CREATE VIEW view_common AS
SELECT DISTINCT
bios821.name,
bios821.grade as grade_821,
bios823.grade as grade_823
FROM
bios821, bios823
WHERE
bios821.name = bios823.name
AND bios821.name IN (
SELECT name
FROM bios823
)
* sqlite://
Done.
[19]:
[]
[20]:
%%sql
SELECT name, grade_823
FROM view_common
WHERE grade_823 > (
SELECT AVG(grade_821)
FROM view_common
)
* sqlite://
Done.
[20]:
| name | grade_823 |
|---|---|
| Alexandra James | 73 |
| Nancy Castaneda | 67 |
| Jennifer Hunt | 86 |
| Kathy Cochran | 74 |
| Cindy Clark | 73 |
| Robert Wong | 91 |
| Sharon Porter | 98 |
Using pandas.¶
[21]:
df = bios821.merge(bios823, on='name', suffixes=['_821', '_823'])
[22]:
df
[22]:
| name | grade_821 | grade_823 | |
|---|---|---|---|
| 0 | Alexandra James | 75 | 73 |
| 1 | Nancy Castaneda | 50 | 67 |
| 2 | Jennifer Hunt | 51 | 86 |
| 3 | Dr. Scott Mendoza MD | 88 | 64 |
| 4 | Kathy Cochran | 51 | 74 |
| 5 | Cindy Clark | 56 | 73 |
| 6 | Robert Wong | 63 | 91 |
| 7 | Sharon Porter | 78 | 98 |
[23]:
df[df.grade_823 > df.grade_821.mean()]
[23]:
| name | grade_821 | grade_823 | |
|---|---|---|---|
| 0 | Alexandra James | 75 | 73 |
| 1 | Nancy Castaneda | 50 | 67 |
| 2 | Jennifer Hunt | 51 | 86 |
| 4 | Kathy Cochran | 51 | 74 |
| 5 | Cindy Clark | 56 | 73 |
| 6 | Robert Wong | 63 | 91 |
| 7 | Sharon Porter | 78 | 98 |
Common table expressions (CTE)¶
CTEs are temporary tables created for a specific query.
[24]:
%%sql
WITH
t1(name) AS (SELECT 'Bob'),
t2(age) AS (SELECT 23)
SELECT * from t1, t2
* sqlite://
Done.
[24]:
| name | age |
|---|---|
| Bob | 23 |
Using CTEs to solve previous problem¶
[25]:
%%sql
WITH common AS (
SELECT DISTINCT
bios821.name,
bios821.grade as grade_821,
bios823.grade as grade_823
FROM
bios821,
bios823
WHERE bios821.name IN (
SELECT name FROM bios823
) AND
bios821.name = bios823.name
)
SELECT name, grade_823
FROM common
WHERE grade_823 > (
SELECT AVG(grade_821)
FROM common
)
* sqlite://
Done.
[25]:
| name | grade_823 |
|---|---|
| Alexandra James | 73 |
| Nancy Castaneda | 67 |
| Jennifer Hunt | 86 |
| Kathy Cochran | 74 |
| Cindy Clark | 73 |
| Robert Wong | 91 |
| Sharon Porter | 98 |
Recursive CTEs¶
Image source: https://cdn.sqlservertutorial.net/wp-content/uploads/SQL-Server-Recursive-CTE-execution-flow.png 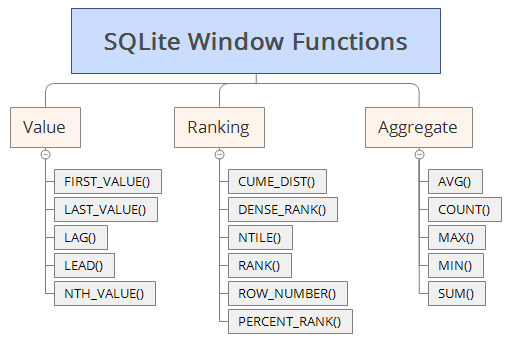
{kind=link}
As a generator¶
[26]:
%%sql
WITH RECURSIVE count(n) AS (
SELECT 1
UNION ALL
SELECT n+1 FROM count WHERe n < 5
)
SELECT * FROM count
* sqlite://
Done.
[26]:
| n |
|---|
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
Generating dates¶
[27]:
%%sql
WITH RECURSIVE make_dates(d) AS (
SELECT '2019-01-15'
UNION ALL
SELECT DATE(d, '+1 MONTHS') FROM make_dates WHERe d < '2019-12'
)
SELECT d AS "Homework due" FROM make_dates
* sqlite://
Done.
[27]:
| Homework due |
|---|
| 2019-01-15 |
| 2019-02-15 |
| 2019-03-15 |
| 2019-04-15 |
| 2019-05-15 |
| 2019-06-15 |
| 2019-07-15 |
| 2019-08-15 |
| 2019-09-15 |
| 2019-10-15 |
| 2019-11-15 |
| 2019-12-15 |
CTEs to do programming in SQL(!)¶
[28]:
%%sql
WITH RECURSIVE fact(n, f) AS (
SELECT 1, 1
UNION ALL
SELECT n+1, (n+1) * f
FROM fact
WHERe n < 5
)
SELECT * FROM fact
LIMIT 5
* sqlite://
Done.
[28]:
| n | f |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 6 |
| 4 | 24 |
| 5 | 120 |
[29]:
%%sql
WITH RECURSIVE fib(n, f1, f2) AS (
SELECT 1, 0, 1
UNION ALL
SELECT n+1, f2, f1+f2
FROM fib
WHERe n < 10
)
SELECT * FROM fib
LIMIT 10
* sqlite://
Done.
[29]:
| n | f1 | f2 |
|---|---|---|
| 1 | 0 | 1 |
| 2 | 1 | 1 |
| 3 | 1 | 2 |
| 4 | 2 | 3 |
| 5 | 3 | 5 |
| 6 | 5 | 8 |
| 7 | 8 | 13 |
| 8 | 13 | 21 |
| 9 | 21 | 34 |
| 10 | 34 | 55 |
A common use of CTEs is to work with naturally recursive structures (trees or graphs)¶
Suppose we have a cell subset taxonomy with parent-child relations. We want to find all descendants of a particular cell type. This is hard to do without recursive CTEs in SQL.
[30]:
%%sql sqlite:///
DROP TABLE IF EXISTS cell;
CREATE TABLE cell(
cell_id integer PRIMARY KEY,
name VARCHAR(30),
parent_id integer
);
INSERT INTO cell (
cell_id,
name,
parent_id
)
VALUES
(1, 'WBC', NULL),
(2, 'Lymphocyte', 1),
(3, 'T Cell', 2),
(4, 'B Cell', 2),
(5, 'NK Cell', 2),
(6, 'T helper cell', 3),
(7, 'T cytotoxic cell', 3),
(8, 'T regulatory cell', 3),
(9, 'Naive B cell', 4),
(10, 'Memory B cell', 4),
(11, 'Plasma cell', 4),
(12, 'Granulocyte', 1),
(13, 'Basophil', 12),
(14, 'Eosinophil', 12),
(15, 'Neutrophil', 12)
Done.
Done.
15 rows affected.
[30]:
[]
[31]:
%%sql
SELECT * FROM cell LIMIT 10
sqlite://
* sqlite:///
Done.
[31]:
| cell_id | name | parent_id |
|---|---|---|
| 1 | WBC | None |
| 2 | Lymphocyte | 1 |
| 3 | T Cell | 2 |
| 4 | B Cell | 2 |
| 5 | NK Cell | 2 |
| 6 | T helper cell | 3 |
| 7 | T cytotoxic cell | 3 |
| 8 | T regulatory cell | 3 |
| 9 | Naive B cell | 4 |
| 10 | Memory B cell | 4 |
[32]:
%%sql
SELECT cell_id, name, parent_id
FROM cell
WHERE name='T Cell'
sqlite://
* sqlite:///
Done.
[32]:
| cell_id | name | parent_id |
|---|---|---|
| 3 | T Cell | 2 |
[33]:
target = 'Lymphocyte'
[34]:
%%sql
WITH RECURSIVE lineage AS (
SELECT
cell_id,
name,
parent_id
FROM
cell
WHERE
name=:target
UNION ALL
SELECT
c.cell_id,
c.name,
c.parent_id
FROM
cell c
INNER JOIN
lineage l
ON
l.cell_id = c.parent_id
)
SELECT * FROM lineage
LIMIT 10
sqlite://
* sqlite:///
Done.
[34]:
| cell_id | name | parent_id |
|---|---|---|
| 2 | Lymphocyte | 1 |
| 4 | B Cell | 2 |
| 5 | NK Cell | 2 |
| 3 | T Cell | 2 |
| 10 | Memory B cell | 4 |
| 9 | Naive B cell | 4 |
| 11 | Plasma cell | 4 |
| 7 | T cytotoxic cell | 3 |
| 6 | T helper cell | 3 |
| 8 | T regulatory cell | 3 |
Window Functions¶
[35]:
np.random.seed(23)
n = 10
df = pd.DataFrame(
dict(person=np.random.choice(['A', 'B', 'C', 'D'], n,),
time=np.random.randint(0, 10, n),
bsl=np.random.randint(50, 400, n)))
[36]:
df.sort_values(['person', 'time'])
[36]:
| person | time | bsl | |
|---|---|---|---|
| 8 | A | 0 | 115 |
| 5 | A | 2 | 237 |
| 2 | A | 3 | 129 |
| 7 | B | 5 | 86 |
| 3 | B | 6 | 396 |
| 4 | C | 1 | 107 |
| 1 | C | 9 | 347 |
| 6 | D | 5 | 89 |
| 9 | D | 5 | 221 |
| 0 | D | 7 | 98 |
[37]:
%sql DROP TABLE IF EXISTS df
sqlite://
* sqlite:///
Done.
[37]:
[]
Magic shortcut to creating a database table from pandas DataFrame.
[38]:
%sql -p df
sqlite://
* sqlite:///
[38]:
'Persisted df'
I’ve given pandas equivalents where possible, but sometimes they are rather unnatural.
[39]:
%%sql
SELECT person, time, bsl, row_number()
OVER () as row_num
FROM df;
sqlite://
* sqlite:///
Done.
[39]:
| person | time | bsl | row_num |
|---|---|---|---|
| D | 7 | 98 | 1 |
| C | 9 | 347 | 2 |
| A | 3 | 129 | 3 |
| B | 6 | 396 | 4 |
| C | 1 | 107 | 5 |
| A | 2 | 237 | 6 |
| D | 5 | 89 | 7 |
| B | 5 | 86 | 8 |
| A | 0 | 115 | 9 |
| D | 5 | 221 | 10 |
[40]:
df.assign(row_num = df.person.expanding(1).count().astype('int'))
[40]:
| person | time | bsl | row_num | |
|---|---|---|---|---|
| 0 | D | 7 | 98 | 1 |
| 1 | C | 9 | 347 | 2 |
| 2 | A | 3 | 129 | 3 |
| 3 | B | 6 | 396 | 4 |
| 4 | C | 1 | 107 | 5 |
| 5 | A | 2 | 237 | 6 |
| 6 | D | 5 | 89 | 7 |
| 7 | B | 5 | 86 | 8 |
| 8 | A | 0 | 115 | 9 |
| 9 | D | 5 | 221 | 10 |
[41]:
%%sql
SELECT person, time, bsl,
lag(bsl, 1) OVER () as lag1,
lead(bsl, 2) OVER () as lead2
FROM df;
sqlite://
* sqlite:///
Done.
[41]:
| person | time | bsl | lag1 | lead2 |
|---|---|---|---|---|
| D | 7 | 98 | None | 129 |
| C | 9 | 347 | 98 | 396 |
| A | 3 | 129 | 347 | 107 |
| B | 6 | 396 | 129 | 237 |
| C | 1 | 107 | 396 | 89 |
| A | 2 | 237 | 107 | 86 |
| D | 5 | 89 | 237 | 115 |
| B | 5 | 86 | 89 | 221 |
| A | 0 | 115 | 86 | None |
| D | 5 | 221 | 115 | None |
[42]:
df_ = df.copy()
df_['lag1'] = df_.bsl.shift(1)
df_['lead2'] = df_.bsl.shift(-2)
df_
[42]:
| person | time | bsl | lag1 | lead2 | |
|---|---|---|---|---|---|
| 0 | D | 7 | 98 | NaN | 129.0 |
| 1 | C | 9 | 347 | 98.0 | 396.0 |
| 2 | A | 3 | 129 | 347.0 | 107.0 |
| 3 | B | 6 | 396 | 129.0 | 237.0 |
| 4 | C | 1 | 107 | 396.0 | 89.0 |
| 5 | A | 2 | 237 | 107.0 | 86.0 |
| 6 | D | 5 | 89 | 237.0 | 115.0 |
| 7 | B | 5 | 86 | 89.0 | 221.0 |
| 8 | A | 0 | 115 | 86.0 | NaN |
| 9 | D | 5 | 221 | 115.0 | NaN |
[43]:
%%sql
SELECT person, time, bsl, row_number()
OVER (ORDER BY person, time)
FROM df;
sqlite://
* sqlite:///
Done.
[43]:
| person | time | bsl | row_number() OVER (ORDER BY person, time) |
|---|---|---|---|
| A | 0 | 115 | 1 |
| A | 2 | 237 | 2 |
| A | 3 | 129 | 3 |
| B | 5 | 86 | 4 |
| B | 6 | 396 | 5 |
| C | 1 | 107 | 6 |
| C | 9 | 347 | 7 |
| D | 5 | 89 | 8 |
| D | 5 | 221 | 9 |
| D | 7 | 98 | 10 |
[44]:
df_ = df.copy()
df_ = df_.sort_values(['person', 'time'])
df_.assign(row_num = df_.person.expanding(1).count().astype('int'))
[44]:
| person | time | bsl | row_num | |
|---|---|---|---|---|
| 8 | A | 0 | 115 | 1 |
| 5 | A | 2 | 237 | 2 |
| 2 | A | 3 | 129 | 3 |
| 7 | B | 5 | 86 | 4 |
| 3 | B | 6 | 396 | 5 |
| 4 | C | 1 | 107 | 6 |
| 1 | C | 9 | 347 | 7 |
| 6 | D | 5 | 89 | 8 |
| 9 | D | 5 | 221 | 9 |
| 0 | D | 7 | 98 | 10 |
[45]:
%%sql
SELECT person, time, bsl, row_number()
OVER (PARTITION BY person ORDER BY time) as row_number
FROM df;
sqlite://
* sqlite:///
Done.
[45]:
| person | time | bsl | row_number |
|---|---|---|---|
| A | 0 | 115 | 1 |
| A | 2 | 237 | 2 |
| A | 3 | 129 | 3 |
| B | 5 | 86 | 1 |
| B | 6 | 396 | 2 |
| C | 1 | 107 | 1 |
| C | 9 | 347 | 2 |
| D | 5 | 89 | 1 |
| D | 5 | 221 | 2 |
| D | 7 | 98 | 3 |
[46]:
df_ = df.copy()
df_ = df_.sort_values(['person', 'time'])
df_['row_number'] = df_.groupby(['person']).cumcount()+1
df_
[46]:
| person | time | bsl | row_number | |
|---|---|---|---|---|
| 8 | A | 0 | 115 | 1 |
| 5 | A | 2 | 237 | 2 |
| 2 | A | 3 | 129 | 3 |
| 7 | B | 5 | 86 | 1 |
| 3 | B | 6 | 396 | 2 |
| 4 | C | 1 | 107 | 1 |
| 1 | C | 9 | 347 | 2 |
| 6 | D | 5 | 89 | 1 |
| 9 | D | 5 | 221 | 2 |
| 0 | D | 7 | 98 | 3 |
[47]:
%%sql
SELECT person, time, bsl, group_concat(bsl, ', ')
OVER (PARTITION BY person ORDER BY time) as window
FROM df;
sqlite://
* sqlite:///
Done.
[47]:
| person | time | bsl | window |
|---|---|---|---|
| A | 0 | 115 | 115 |
| A | 2 | 237 | 115, 237 |
| A | 3 | 129 | 115, 237, 129 |
| B | 5 | 86 | 86 |
| B | 6 | 396 | 86, 396 |
| C | 1 | 107 | 107 |
| C | 9 | 347 | 107, 347 |
| D | 5 | 89 | 89, 221 |
| D | 5 | 221 | 89, 221 |
| D | 7 | 98 | 89, 221, 98 |
[48]:
df_['window'] = (
df_.groupby('person').
apply(lambda x: pd.Series([x.bsl.iloc[:(i+1)].values
for i in pd.Series(np.arange(len(x)))]))
).values
df_['window'] = df_.window.apply(lambda x: ','.join(map(str, x)))
df_
[48]:
| person | time | bsl | row_number | window | |
|---|---|---|---|---|---|
| 8 | A | 0 | 115 | 1 | 115 |
| 5 | A | 2 | 237 | 2 | 115,237 |
| 2 | A | 3 | 129 | 3 | 115,237,129 |
| 7 | B | 5 | 86 | 1 | 86 |
| 3 | B | 6 | 396 | 2 | 86,396 |
| 4 | C | 1 | 107 | 1 | 107 |
| 1 | C | 9 | 347 | 2 | 107,347 |
| 6 | D | 5 | 89 | 1 | 89 |
| 9 | D | 5 | 221 | 2 | 89,221 |
| 0 | D | 7 | 98 | 3 | 89,221,98 |
[49]:
%%sql
SELECT person, time, bsl, group_concat(bsl, ', ')
OVER (
PARTITION BY person
ORDER BY time
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
) as window
FROM df;
sqlite://
* sqlite:///
Done.
[49]:
| person | time | bsl | window |
|---|---|---|---|
| A | 0 | 115 | 115, 237 |
| A | 2 | 237 | 115, 237, 129 |
| A | 3 | 129 | 237, 129 |
| B | 5 | 86 | 86, 396 |
| B | 6 | 396 | 86, 396 |
| C | 1 | 107 | 107, 347 |
| C | 9 | 347 | 107, 347 |
| D | 5 | 89 | 89, 221 |
| D | 5 | 221 | 89, 221, 98 |
| D | 7 | 98 | 221, 98 |
[50]:
df_['window'] = (
df_.groupby('person').
apply(lambda x: pd.Series([x.bsl.iloc[(i-len(x)-1):(i+2)].values
for i in pd.Series(np.arange(len(x)))]))
).values
df_['window'] = df_.window.apply(lambda x: ','.join(map(str, x)))
df_
[50]:
| person | time | bsl | row_number | window | |
|---|---|---|---|---|---|
| 8 | A | 0 | 115 | 1 | 115,237 |
| 5 | A | 2 | 237 | 2 | 115,237,129 |
| 2 | A | 3 | 129 | 3 | 237,129 |
| 7 | B | 5 | 86 | 1 | 86,396 |
| 3 | B | 6 | 396 | 2 | 86,396 |
| 4 | C | 1 | 107 | 1 | 107,347 |
| 1 | C | 9 | 347 | 2 | 107,347 |
| 6 | D | 5 | 89 | 1 | 89,221 |
| 9 | D | 5 | 221 | 2 | 89,221,98 |
| 0 | D | 7 | 98 | 3 | 221,98 |
[51]:
%%sql
SELECT person, time, bsl,
row_number() OVER win AS row_number,
rank() OVER win AS rank,
dense_rank() OVER win AS dense_rank,
percent_rank() OVER win AS percent_rank,
cume_dist() OVER win AS cume_dist
FROM df
WINDOW win AS (ORDER BY person);
sqlite://
* sqlite:///
Done.
[51]:
| person | time | bsl | row_number | rank | dense_rank | percent_rank | cume_dist |
|---|---|---|---|---|---|---|---|
| A | 3 | 129 | 1 | 1 | 1 | 0.0 | 0.3 |
| A | 2 | 237 | 2 | 1 | 1 | 0.0 | 0.3 |
| A | 0 | 115 | 3 | 1 | 1 | 0.0 | 0.3 |
| B | 6 | 396 | 4 | 4 | 2 | 0.3333333333333333 | 0.5 |
| B | 5 | 86 | 5 | 4 | 2 | 0.3333333333333333 | 0.5 |
| C | 9 | 347 | 6 | 6 | 3 | 0.5555555555555556 | 0.7 |
| C | 1 | 107 | 7 | 6 | 3 | 0.5555555555555556 | 0.7 |
| D | 7 | 98 | 8 | 8 | 4 | 0.7777777777777778 | 1.0 |
| D | 5 | 89 | 9 | 8 | 4 | 0.7777777777777778 | 1.0 |
| D | 5 | 221 | 10 | 8 | 4 | 0.7777777777777778 | 1.0 |
[52]:
df_ = df.copy()
df_ = df_.sort_values(['person'])
df_['row_num'] = df_['person'].expanding(1).count().astype('int')
df_['rank'] = df_['person'].rank(method='min').astype('int')
df_['dense_rank'] = df_['person'].rank(method='dense').astype('int')
df_['percent_rank'] = (df_.person.rank(method='min') - 1) / (df_.person.count()-1)
df_['cume_dist'] = df_['person'].rank(method='max', pct=True)
df_
[52]:
| person | time | bsl | row_num | rank | dense_rank | percent_rank | cume_dist | |
|---|---|---|---|---|---|---|---|---|
| 2 | A | 3 | 129 | 1 | 1 | 1 | 0.000000 | 0.3 |
| 5 | A | 2 | 237 | 2 | 1 | 1 | 0.000000 | 0.3 |
| 8 | A | 0 | 115 | 3 | 1 | 1 | 0.000000 | 0.3 |
| 3 | B | 6 | 396 | 4 | 4 | 2 | 0.333333 | 0.5 |
| 7 | B | 5 | 86 | 5 | 4 | 2 | 0.333333 | 0.5 |
| 1 | C | 9 | 347 | 6 | 6 | 3 | 0.555556 | 0.7 |
| 4 | C | 1 | 107 | 7 | 6 | 3 | 0.555556 | 0.7 |
| 0 | D | 7 | 98 | 8 | 8 | 4 | 0.777778 | 1.0 |
| 6 | D | 5 | 89 | 9 | 8 | 4 | 0.777778 | 1.0 |
| 9 | D | 5 | 221 | 10 | 8 | 4 | 0.777778 | 1.0 |
[53]:
scores = pd.DataFrame(dict(scores=np.random.randint(0, 10, 10)))
scores
[53]:
| scores | |
|---|---|
| 0 | 6 |
| 1 | 7 |
| 2 | 3 |
| 3 | 6 |
| 4 | 9 |
| 5 | 2 |
| 6 | 3 |
| 7 | 0 |
| 8 | 8 |
| 9 | 6 |
[54]:
%sql -p scores
sqlite://
* sqlite:///
[54]:
'Persisted scores'
[55]:
%%sql
SELECT scores, NTILE(4)
OVER (
-- PARTITION BY scores
ORDER BY scores
) AS quartile
FROM scores
sqlite://
* sqlite:///
Done.
[55]:
| scores | quartile |
|---|---|
| 0 | 1 |
| 2 | 1 |
| 3 | 1 |
| 3 | 2 |
| 6 | 2 |
| 6 | 2 |
| 6 | 3 |
| 7 | 3 |
| 8 | 4 |
| 9 | 4 |
Note: See this for an explanation of the difference between NTILE and qcut
[56]:
quartiles = pd.qcut(scores.scores, 4, labels=[1,2,3,4])
scores['quantile'] = quartiles
scores.sort_values('scores')
[56]:
| scores | quantile | |
|---|---|---|
| 7 | 0 | 1 |
| 5 | 2 | 1 |
| 2 | 3 | 1 |
| 6 | 3 | 1 |
| 0 | 6 | 2 |
| 3 | 6 | 2 |
| 9 | 6 | 2 |
| 1 | 7 | 4 |
| 8 | 8 | 4 |
| 4 | 9 | 4 |
The sqlite3 implementation of LAST_VALUE seems to be buggy.
[57]:
%%sql
SELECT person, time, bsl,
SUM(bsl) OVER win AS bsl_sum,
AVG(bsl) OVER win AS bsl_avg,
MIN(bsl) OVER win AS bsl_min,
MAX(bsl) over win as bsl_max,
FIRST_VALUE(bsl) OVER win as bsl_start,
LAST_VALUE(bsl) OVER win as bsl_end
FROM df
WINDOW win AS (PARTITION BY person ORDER BY time);
sqlite://
* sqlite:///
Done.
[57]:
| person | time | bsl | bsl_sum | bsl_avg | bsl_min | bsl_max | bsl_start | bsl_end |
|---|---|---|---|---|---|---|---|---|
| A | 0 | 115 | 115 | 115.0 | 115 | 115 | 115 | 115 |
| A | 2 | 237 | 352 | 176.0 | 115 | 237 | 115 | 237 |
| A | 3 | 129 | 481 | 160.33333333333334 | 115 | 237 | 115 | 129 |
| B | 5 | 86 | 86 | 86.0 | 86 | 86 | 86 | 86 |
| B | 6 | 396 | 482 | 241.0 | 86 | 396 | 86 | 396 |
| C | 1 | 107 | 107 | 107.0 | 107 | 107 | 107 | 107 |
| C | 9 | 347 | 454 | 227.0 | 107 | 347 | 107 | 347 |
| D | 5 | 89 | 310 | 155.0 | 89 | 221 | 89 | 221 |
| D | 5 | 221 | 310 | 155.0 | 89 | 221 | 89 | 221 |
| D | 7 | 98 | 408 | 136.0 | 89 | 221 | 89 | 98 |
[58]:
g = df.groupby('person')
g.first()
[58]:
| time | bsl | |
|---|---|---|
| person | ||
| A | 3 | 129 |
| B | 6 | 396 |
| C | 9 | 347 |
| D | 7 | 98 |
[59]:
df_ = df.copy()
df_ = df_.sort_values(['person', 'time'])
df_['bsl_sum'] = df_.groupby(['person'])['bsl'].cumsum()
df_['bsl_avg'] = df_.groupby(['person']).expanding().agg({'bsl': 'mean'}).values
df_['bsl_min'] = df_.groupby(['person'])['bsl'].cummin()
df_['bsl_max'] = df_.groupby(['person'])['bsl'].cummax()
df_['bsl_start'] = df_.groupby(['person'])['bsl'].transform('first')
df_['bsl_end'] = df_.groupby(['person'])['bsl'].transform('last')
df_
[59]:
| person | time | bsl | bsl_sum | bsl_avg | bsl_min | bsl_max | bsl_start | bsl_end | |
|---|---|---|---|---|---|---|---|---|---|
| 8 | A | 0 | 115 | 115 | 115.000000 | 115 | 115 | 115 | 129 |
| 5 | A | 2 | 237 | 352 | 176.000000 | 115 | 237 | 115 | 129 |
| 2 | A | 3 | 129 | 481 | 160.333333 | 115 | 237 | 115 | 129 |
| 7 | B | 5 | 86 | 86 | 86.000000 | 86 | 86 | 86 | 396 |
| 3 | B | 6 | 396 | 482 | 241.000000 | 86 | 396 | 86 | 396 |
| 4 | C | 1 | 107 | 107 | 107.000000 | 107 | 107 | 107 | 347 |
| 1 | C | 9 | 347 | 454 | 227.000000 | 107 | 347 | 107 | 347 |
| 6 | D | 5 | 89 | 89 | 89.000000 | 89 | 89 | 89 | 98 |
| 9 | D | 5 | 221 | 310 | 155.000000 | 89 | 221 | 89 | 98 |
| 0 | D | 7 | 98 | 408 | 136.000000 | 89 | 221 | 89 | 98 |
[60]:
%%sql
SELECT person, time, bsl,
GROUP_CONCAT(CAST(bsl AS TEXT), ', ') OVER win AS vals,
SUM(bsl) OVER win AS bsl_sum,
AVG(bsl) OVER win AS bsl_avg
FROM df
WINDOW win AS (
PARTITION BY person
ORDER BY time
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
)
ORDER BY person, time;
sqlite://
* sqlite:///
Done.
[60]:
| person | time | bsl | vals | bsl_sum | bsl_avg |
|---|---|---|---|---|---|
| A | 0 | 115 | 115, 237 | 352 | 176.0 |
| A | 2 | 237 | 115, 237, 129 | 481 | 160.33333333333334 |
| A | 3 | 129 | 237, 129 | 366 | 183.0 |
| B | 5 | 86 | 86, 396 | 482 | 241.0 |
| B | 6 | 396 | 86, 396 | 482 | 241.0 |
| C | 1 | 107 | 107, 347 | 454 | 227.0 |
| C | 9 | 347 | 107, 347 | 454 | 227.0 |
| D | 5 | 89 | 89, 221 | 310 | 155.0 |
| D | 5 | 221 | 89, 221, 98 | 408 | 136.0 |
| D | 7 | 98 | 221, 98 | 319 | 159.5 |
[61]:
df_ = df.copy()
df_ = df_.sort_values(['person', 'time'])
df_['bsl_sum'] = (df_.groupby('person').
bsl.apply(lambda x: x.rolling(3, min_periods=0, center=True).sum()))
df_['bsl_avg'] = (df_.groupby('person').
bsl.apply(lambda x: x.rolling(3, min_periods=0, center=True).mean()))
df_
[61]:
| person | time | bsl | bsl_sum | bsl_avg | |
|---|---|---|---|---|---|
| 8 | A | 0 | 115 | 352.0 | 176.000000 |
| 5 | A | 2 | 237 | 481.0 | 160.333333 |
| 2 | A | 3 | 129 | 366.0 | 183.000000 |
| 7 | B | 5 | 86 | 482.0 | 241.000000 |
| 3 | B | 6 | 396 | 482.0 | 241.000000 |
| 4 | C | 1 | 107 | 454.0 | 227.000000 |
| 1 | C | 9 | 347 | 454.0 | 227.000000 |
| 6 | D | 5 | 89 | 310.0 | 155.000000 |
| 9 | D | 5 | 221 | 408.0 | 136.000000 |
| 0 | D | 7 | 98 | 319.0 | 159.500000 |
For Range, all rows with the same ORDER BY value are considered peers.
[62]:
%%sql
SELECT person, time, bsl,
GROUP_CONCAT(CAST(bsl AS TEXT), ', ') OVER win AS vals,
SUM(bsl) OVER win AS bsl_sum,
AVG(bsl) OVER win AS bsl_avg
FROM df
WINDOW win AS (
ORDER BY person, time
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
)
ORDER BY person, time;
sqlite://
* sqlite:///
Done.
[62]:
| person | time | bsl | vals | bsl_sum | bsl_avg |
|---|---|---|---|---|---|
| A | 0 | 115 | 115 | 115 | 115.0 |
| A | 2 | 237 | 115, 237 | 352 | 176.0 |
| A | 3 | 129 | 115, 237, 129 | 481 | 160.33333333333334 |
| B | 5 | 86 | 115, 237, 129, 86 | 567 | 141.75 |
| B | 6 | 396 | 115, 237, 129, 86, 396 | 963 | 192.6 |
| C | 1 | 107 | 115, 237, 129, 86, 396, 107 | 1070 | 178.33333333333334 |
| C | 9 | 347 | 115, 237, 129, 86, 396, 107, 347 | 1417 | 202.42857142857142 |
| D | 5 | 89 | 115, 237, 129, 86, 396, 107, 347, 89 | 1506 | 188.25 |
| D | 5 | 221 | 115, 237, 129, 86, 396, 107, 347, 89, 221 | 1727 | 191.88888888888889 |
| D | 7 | 98 | 115, 237, 129, 86, 396, 107, 347, 89, 221, 98 | 1825 | 182.5 |
[63]:
df_ = df.copy()
df_ = df_.sort_values(['person', 'time'])
df_['bsl_sum'] = df_.bsl.expanding().sum().astype('int')
df_['bsl_avg'] = df_.bsl.expanding().mean()
df_
[63]:
| person | time | bsl | bsl_sum | bsl_avg | |
|---|---|---|---|---|---|
| 8 | A | 0 | 115 | 115 | 115.000000 |
| 5 | A | 2 | 237 | 352 | 176.000000 |
| 2 | A | 3 | 129 | 481 | 160.333333 |
| 7 | B | 5 | 86 | 567 | 141.750000 |
| 3 | B | 6 | 396 | 963 | 192.600000 |
| 4 | C | 1 | 107 | 1070 | 178.333333 |
| 1 | C | 9 | 347 | 1417 | 202.428571 |
| 6 | D | 5 | 89 | 1506 | 188.250000 |
| 9 | D | 5 | 221 | 1727 | 191.888889 |
| 0 | D | 7 | 98 | 1825 | 182.500000 |
[64]:
%%sql
SELECT person, time, bsl,
GROUP_CONCAT(CAST(bsl AS TEXT), ', ') OVER win AS vals,
SUM(bsl) OVER win AS bsl_sum,
AVG(bsl) OVER win AS bsl_avg
FROM df
WINDOW win AS (
ORDER BY person
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
)
ORDER BY person, time;
sqlite://
* sqlite:///
Done.
[64]:
| person | time | bsl | vals | bsl_sum | bsl_avg |
|---|---|---|---|---|---|
| A | 0 | 115 | 129, 237, 115 | 481 | 160.33333333333334 |
| A | 2 | 237 | 129, 237, 115 | 481 | 160.33333333333334 |
| A | 3 | 129 | 129, 237, 115 | 481 | 160.33333333333334 |
| B | 5 | 86 | 129, 237, 115, 396, 86 | 963 | 192.6 |
| B | 6 | 396 | 129, 237, 115, 396, 86 | 963 | 192.6 |
| C | 1 | 107 | 129, 237, 115, 396, 86, 347, 107 | 1417 | 202.42857142857142 |
| C | 9 | 347 | 129, 237, 115, 396, 86, 347, 107 | 1417 | 202.42857142857142 |
| D | 5 | 89 | 129, 237, 115, 396, 86, 347, 107, 98, 89, 221 | 1825 | 182.5 |
| D | 5 | 221 | 129, 237, 115, 396, 86, 347, 107, 98, 89, 221 | 1825 | 182.5 |
| D | 7 | 98 | 129, 237, 115, 396, 86, 347, 107, 98, 89, 221 | 1825 | 182.5 |
[65]:
df_ = df.copy()
df_ = df_.sort_values(['person', 'time'])
df_['bsl_sum'] = df_['bsl'].cumsum().groupby(df_['person']).transform('last')
df_['bsl_sum'] = df_['bsl'].expanding().mean().groupby(df_['person']).transform('last')
df_
[65]:
| person | time | bsl | bsl_sum | |
|---|---|---|---|---|
| 8 | A | 0 | 115 | 160.333333 |
| 5 | A | 2 | 237 | 160.333333 |
| 2 | A | 3 | 129 | 160.333333 |
| 7 | B | 5 | 86 | 192.600000 |
| 3 | B | 6 | 396 | 192.600000 |
| 4 | C | 1 | 107 | 202.428571 |
| 1 | C | 9 | 347 | 202.428571 |
| 6 | D | 5 | 89 | 182.500000 |
| 9 | D | 5 | 221 | 182.500000 |
| 0 | D | 7 | 98 | 182.500000 |