Spark SQL¶
Using Spark SQL and DataFrames results in performance that is comparable to native compiled Scala code. This is not true in general if you use the low-level RDD API.
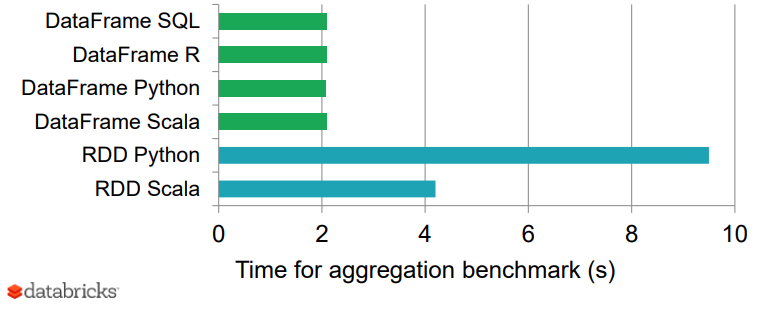
Source: https://miro.medium.com/max/1524/1*Kolwjg356xdqPv-8JmQGRQ.png
The improvement in efficiency is largely due to the Catalyst optimizer, which applies rule-based and cost-based optimization. Optimization occurs in 4 phases:
Analysis
Generate an abstract syntax tree
Resolve names using internal catalog
Logical optimization
Construct plans using rule-based optimization
Assign costs to each plan using cost-based optimization
Physical planning
Generate a physical plan using operations available in Spark execution engine
Code generation
Generate Java bytecode to run on each machine
Generates compact RDD code for final execution
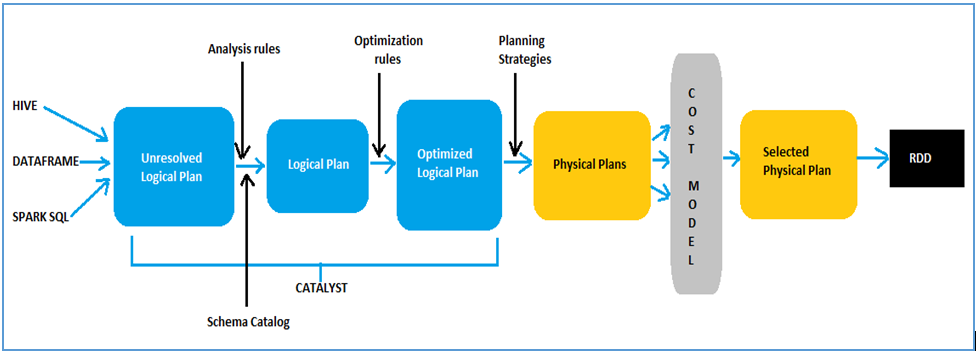
Source: https://miro.medium.com/max/1400/1*_DdwvGk23tB3p1aLQB3Q4A.pngjpg
[1]:
from pyspark.sql import SparkSession
[2]:
spark = (
SparkSession.builder
.master("local")
.appName("BIOS-823")
.config("spark.executor.cores", 4)
.getOrCreate()
)
[3]:
import pandas as pd
[4]:
df = spark.createDataFrame(pd.DataFrame(dict(a=range(6), b=list('aabbcc'))))
[5]:
df.show()
+---+---+
| a| b|
+---+---+
| 0| a|
| 1| a|
| 2| b|
| 3| b|
| 4| c|
| 5| c|
+---+---+
Read the DataFrame into a temporary view for SQL queries.
[6]:
df.createOrReplaceTempView('df_table')
If you want to create a permanent table, use this
df.write.saveAsTable('df_table')
[7]:
spark.catalog.listDatabases()
[7]:
[Database(name='default', description='Default Hive database', locationUri='file:/Users/cliburnchan/_teach/bios-823-2020/notebooks/spark-warehouse')]
[8]:
spark.catalog.listTables()
[8]:
[Table(name='df_table', database=None, description=None, tableType='TEMPORARY', isTemporary=True)]
To convert a table back inot a DataFrame
[9]:
spark.sql('SELECT * FROM df_table').show()
+---+---+
| a| b|
+---+---+
| 0| a|
| 1| a|
| 2| b|
| 3| b|
| 4| c|
| 5| c|
+---+---+
[10]:
spark.table('df_table').show()
+---+---+
| a| b|
+---+---+
| 0| a|
| 1| a|
| 2| b|
| 3| b|
| 4| c|
| 5| c|
+---+---+
Standard SQL Queries¶
All Spark SQL queries return a DataFrame.
[11]:
spark.sql('''
SELECT a, b FROM df_table
''').show()
+---+---+
| a| b|
+---+---+
| 0| a|
| 1| a|
| 2| b|
| 3| b|
| 4| c|
| 5| c|
+---+---+
[12]:
spark.sql('''
SELECT *
FROM df_table
WHERE b='b'
''').show()
+---+---+
| a| b|
+---+---+
| 2| b|
| 3| b|
+---+---+
[13]:
spark.sql('''
SELECT b, mean(a) AS avg, std(a) AS std
FROM df_table
GROUP BY b
ORDER BY b
''').show()
+---+---+------------------+
| b|avg| std|
+---+---+------------------+
| a|0.5|0.7071067811865476|
| b|2.5|0.7071067811865476|
| c|4.5|0.7071067811865476|
+---+---+------------------+
Functions¶
[14]:
spark.sql('''
SHOW FUNCTIONS "c*"
''').show(50)
+-----------------+
| function|
+-----------------+
| cardinality|
| case|
| cast|
| cbrt|
| ceil|
| ceiling|
| char|
| char_length|
| character_length|
| chr|
| coalesce|
| collect_list|
| collect_set|
| concat|
| concat_ws|
| conv|
| corr|
| cos|
| cosh|
| cot|
| count|
| count_if|
| count_min_sketch|
| covar_pop|
| covar_samp|
| crc32|
| cube|
| cume_dist|
| current_database|
| current_date|
|current_timestamp|
+-----------------+
[15]:
from pyspark.sql import functions
[16]:
sorted([f for f in dir(functions) if f.startswith('c')])
[16]:
['cbrt',
'ceil',
'coalesce',
'col',
'collect_list',
'collect_set',
'column',
'concat',
'concat_ws',
'conv',
'corr',
'cos',
'cosh',
'count',
'countDistinct',
'covar_pop',
'covar_samp',
'crc32',
'create_map',
'cume_dist',
'current_date',
'current_timestamp']
Complex Types¶
Structs¶
[17]:
df1 = spark.sql('''
SELECT a, b, (a, b) AS struct FROM df_table
''')
[18]:
df1.show()
+---+---+------+
| a| b|struct|
+---+---+------+
| 0| a|[0, a]|
| 1| a|[1, a]|
| 2| b|[2, b]|
| 3| b|[3, b]|
| 4| c|[4, c]|
| 5| c|[5, c]|
+---+---+------+
[19]:
df1.createOrReplaceTempView('df1_table')
[20]:
spark.sql('''
SELECT struct.a, struct.b FROM df1_table
''').show()
+---+---+
| a| b|
+---+---+
| 0| a|
| 1| a|
| 2| b|
| 3| b|
| 4| c|
| 5| c|
+---+---+
Lists¶
[21]:
df2 = spark.sql('''
SELECT b, collect_list(a) as list
FROM df_table
GROUP BY b
ORDER BY b
''')
[22]:
df2.createOrReplaceTempView('df2_table')
[23]:
df2.show()
+---+------+
| b| list|
+---+------+
| a|[0, 1]|
| b|[2, 3]|
| c|[4, 5]|
+---+------+
[24]:
spark.sql('''
SELECT b, explode(list) as a
FROM df2_table
''').show()
+---+---+
| b| a|
+---+---+
| a| 0|
| a| 1|
| b| 2|
| b| 3|
| c| 4|
| c| 5|
+---+---+
Maps¶
[25]:
from pyspark.sql.functions import create_map
[26]:
from itertools import chain
[27]:
df3 = df.select('a', 'b', create_map('b', 'a').alias('map'))
[28]:
df3.createOrReplaceTempView('df3_table')
[29]:
df3.show()
+---+---+--------+
| a| b| map|
+---+---+--------+
| 0| a|[a -> 0]|
| 1| a|[a -> 1]|
| 2| b|[b -> 2]|
| 3| b|[b -> 3]|
| 4| c|[c -> 4]|
| 5| c|[c -> 5]|
+---+---+--------+
[30]:
spark.sql('''
SELECT a, b, map['c'] FROM df3_table
''').na.drop().show()
+---+---+------+
| a| b|map[c]|
+---+---+------+
| 4| c| 4|
| 5| c| 5|
+---+---+------+
[31]:
df3.select('a', 'b', 'map.c').filter('c is not null').show()
+---+---+---+
| a| b| c|
+---+---+---+
| 4| c| 4|
| 5| c| 5|
+---+---+---+
[ ]: