Spark Structured Streaming¶
Data set
Review of Spark DataFrames and SQL
Concepts of structured streaming
Sources and sinks
Stateless operations
Stateful operations
Output modes
Windowed operations
Watermarks
Joining with streams
Data set¶
We will work with the Heterogeneity Activity Recognition Data Set from the UCI Machine Learning Repository. A summary of the dataset from the repository:
The activity recognition data set contains the readings of two motion sensors commonly found in smartphones. Reading were recorded while users executed activities scripted in no specific order carrying smartwatches and smartphones.
Activities: ‘Biking’, ‘Sitting’, ‘Standing’, ‘Walking’, ‘Stair Up’ and ‘Stair down’.
Sensors: Sensors: Two embedded sensors, i.e., Accelerometer and Gyroscope, sampled at the highest frequency the respective device allows.
Devices: 4 smartwatches (2 LG watches, 2 Samsung Galaxy Gears) 8 smartphones (2 Samsung Galaxy S3 mini, 2 Samsung Galaxy S3, 2 LG Nexus 4, 2 Samsung Galaxy S+)
Recordings: 9 users
The data consists of the following fields :
‘Index’, ‘Arrival_Time’, ‘Creation_Time’, ‘x’, ‘y’, ‘z’, ‘User’, ‘Model’, ‘Device’, ‘gt’
where gt is the ground truth (activity label) and x, y, z are the motion sensor readings. The Model refers to the wearable used, while the Device refers to which sensor (accelerometer or gyroscope) the readings came from.
This is used as an example since the analysis of streaming data from wearables (e.g. a medical emergency) is an important use case for streaming data in medicine. The data has been converted to a JSON format and the 6 million plus observations stored across 80 files.
If you want to the data to experiment with:
wget https://www.dropbox.com/s/8zgrpu4o3nqdcgh/activity-data.zip
Start Spark¶
[1]:
import string
from pyspark.sql import SparkSession
from pyspark.streaming import StreamingContext
[2]:
spark = (
SparkSession.builder
.master("local")
.appName("BIOS-823")
.config("spark.executor.cores", 4)
.getOrCreate()
)
Review of standard Spark processing with DataFrames and SQL¶
Not runnig as it takes a while.
spark.read.json('json/activity-data').count()
Out[3]: 6240991
Read one file¶
Note the use of schema inference.
[3]:
uri = 'json/activity-data/part-00000-tid-730451297822678341-1dda7027-2071-4d73-a0e2-7fb6a91e1d1f-0-c000.json'
[4]:
df = spark.read.json(uri)
[5]:
df.printSchema()
root
|-- Arrival_Time: long (nullable = true)
|-- Creation_Time: long (nullable = true)
|-- Device: string (nullable = true)
|-- Index: long (nullable = true)
|-- Model: string (nullable = true)
|-- User: string (nullable = true)
|-- gt: string (nullable = true)
|-- x: double (nullable = true)
|-- y: double (nullable = true)
|-- z: double (nullable = true)
[6]:
df.show(3)
+-------------+-------------+--------+-----+------+----+-----+-------------+------------+-------------+
| Arrival_Time|Creation_Time| Device|Index| Model|User| gt| x| y| z|
+-------------+-------------+--------+-----+------+----+-----+-------------+------------+-------------+
|1424686735000|1424686733000|nexus4_1| 35|nexus4| g|stand| 0.0014038086| 5.0354E-4|-0.0124053955|
|1424686735000|1424686733000|nexus4_1| 76|nexus4| g|stand|-0.0039367676| 0.026138306| -0.01133728|
|1424686736000|1424686734000|nexus4_1| 115|nexus4| g|stand| 0.003540039|-0.034744263| -0.019882202|
+-------------+-------------+--------+-----+------+----+-----+-------------+------------+-------------+
only showing top 3 rows
Using SQL¶
[7]:
df.createOrReplaceTempView('activity')
[8]:
spark.sql('SELECT * FROM activity LIMIT 3').show()
+-------------+-------------+--------+-----+------+----+-----+-------------+------------+-------------+
| Arrival_Time|Creation_Time| Device|Index| Model|User| gt| x| y| z|
+-------------+-------------+--------+-----+------+----+-----+-------------+------------+-------------+
|1424686735000|1424686733000|nexus4_1| 35|nexus4| g|stand| 0.0014038086| 5.0354E-4|-0.0124053955|
|1424686735000|1424686733000|nexus4_1| 76|nexus4| g|stand|-0.0039367676| 0.026138306| -0.01133728|
|1424686736000|1424686734000|nexus4_1| 115|nexus4| g|stand| 0.003540039|-0.034744263| -0.019882202|
+-------------+-------------+--------+-----+------+----+-----+-------------+------------+-------------+
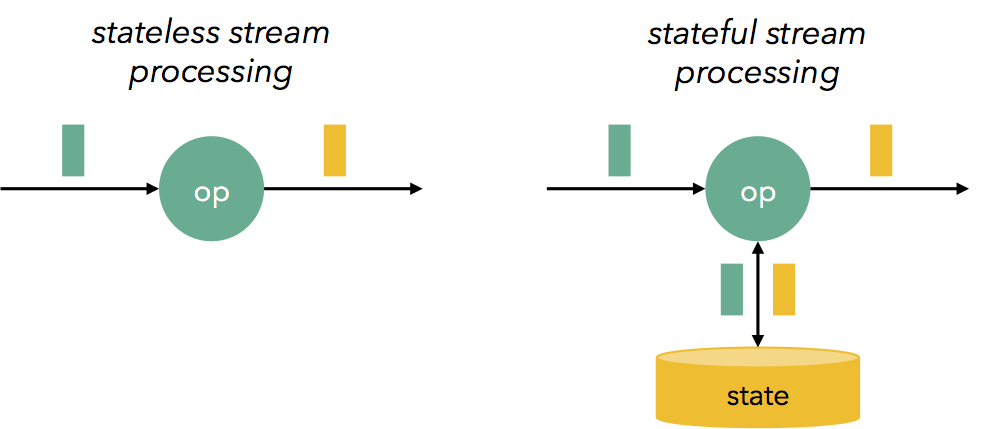
Stateless operations¶
Stateless operations process one row at a time.
[9]:
import pyspark.sql.functions as F
Filter¶
[10]:
df.filter(F.expr('User')=='a').show(3)
+-------------+-------------+--------+-----+------+----+-----+------------+-------------+------------+
| Arrival_Time|Creation_Time| Device|Index| Model|User| gt| x| y| z|
+-------------+-------------+--------+-----+------+----+-----+------------+-------------+------------+
|1424696634000|1424696632000|nexus4_1| 22|nexus4| a|stand|0.0062713623| -0.013442993|-0.009490967|
|1424696634000|1424696632000|nexus4_1| 78|nexus4| a|stand|-0.040725708| -0.016647339| 0.072753906|
|1424696635000|1424698481000|nexus4_2| 49|nexus4| a|stand| -0.04573059|-0.0140686035| 0.08921814|
+-------------+-------------+--------+-----+------+----+-----+------------+-------------+------------+
only showing top 3 rows
Time conversion¶
Convert from Unix epoch to standard format.
[11]:
(
df.select(F.from_unixtime(F.expr('Arrival_Time'),
'yyyy-MM-dd HH:mm:ss').alias('Arrival'))
).show(3, truncate=False)
+---------------------+
|Arrival |
+---------------------+
|+47116-07-11 15:16:40|
|+47116-07-11 15:16:40|
|+47116-07-11 15:33:20|
+---------------------+
only showing top 3 rows
Stateful operations¶
Need to aggregate data over multiple rows
[12]:
(
df.groupBy('User', 'gt').mean('x', 'y', 'z').sort('User', 'gt')
).show()
+----+----------+--------------------+--------------------+--------------------+
|User| gt| avg(x)| avg(y)| avg(z)|
+----+----------+--------------------+--------------------+--------------------+
| a| bike| 0.08286326523323344|-0.02426324084800...| -0.1662348217003992|
| a| null|-0.01308972796540...|0.016658997597921752| 0.04942386999523227|
| a| sit|-2.12969390963855...|-1.50075401673359...|0.001048883435073...|
| a|stairsdown| 0.23440874162122333|-0.06719274877160608| -0.3077443049653919|
| a| stairsup|-0.29239928706342583|-0.00677555257509...| 0.31678605306|
| a| stand|-0.00177360789606...|0.001089580071408...|0.001844132059828448|
| a| walk|0.019868167564847505|-0.02196182985947...|-0.01037372278081...|
| b| bike|0.007747435248372937| 0.01460614637146433|-0.02048030271908635|
| b| null|0.006628031256594217|-0.01005675819492...|0.024657572641956556|
| b| sit|7.738246112637349E-4|0.001047714316483...|-0.00112005380650...|
| b|stairsdown| -0.1337819220130277|-0.03978477199688...| 0.4430138123083492|
| b| stairsup| 0.1908027992841166|-0.04446313425753646|-0.36332664294651545|
| b| stand|-2.50695839259927...|-1.48484005595668...|-0.00105500472075...|
| b| walk|-0.00202879781863...|-0.02067295743016658|-0.00539236749586...|
| c| bike|0.048871796901853976|-0.01610419329918887|-0.14889040097647727|
| c| null|-0.00153568544845...|-0.00134610721863...|0.001905112306683...|
| c| sit|-5.94906131651372...|-3.68963991513762...|0.001000477139678...|
| c|stairsdown| 0.2281934003521868|-0.00901284850815...|-0.26389999844155076|
| c| stairsup| -0.2585194447920258|-0.01185626514694...| 0.3040023440573634|
| c| stand|-0.00204057011630716|0.001435063434771...|0.001349290326747...|
+----+----------+--------------------+--------------------+--------------------+
only showing top 20 rows
Structured Streaming Concepts¶
Streaming data¶
Each time a trigger occurs, new data is read into the stream.
Minibatch - a new read is triggered once the previous minibatch is processed (default)
Fixed interval - e.g. every 5 minutes
One-time - spin up cluster, process all data, then stop (economical for infrequent jobs)
Continuous (for low latency applications ~ 1 ms c.f. minibatch ~ 100 ms)
 Source: https://spark.apache.org/docs/latest/img/structured-streaming-model.png
Source: https://spark.apache.org/docs/latest/img/structured-streaming-model.png
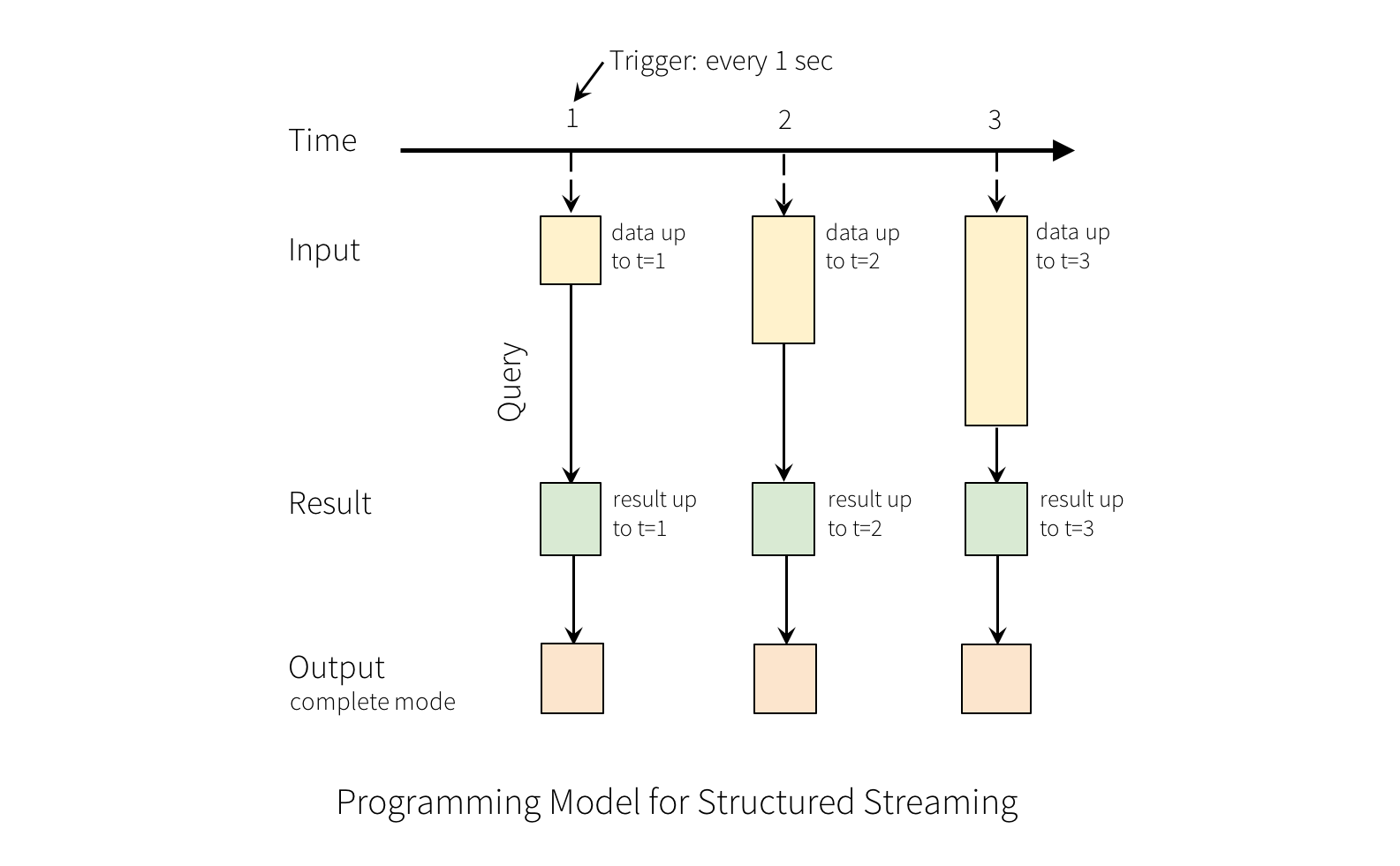{kind=link}
Query on a stream is conceptually an unbounded table updated in mini-batches¶
Reference: Structured Streaming Programming Guide
Sources and sinks¶
Sources¶
Files
Kafka (an open-source distributed event streaming platform)
Socket (for testing)
Rate (for testing)
Sinks¶
File
Kafka
Console (for testing)
Memory (for testing)
Foreach sink (Runs arbitrary computation on the records in the output)
{kind=link}
Output modes¶
appendis useful for stateless operationscompleteandupdatemodes are useful for stateful operations
Source: https://vishnuviswanath.com/img/spark_structured_streaming/output_modes.png
{kind=link}
Windowed operations¶
Source: https://spark.apache.org/docs/latest/img/structured-streaming-window.png
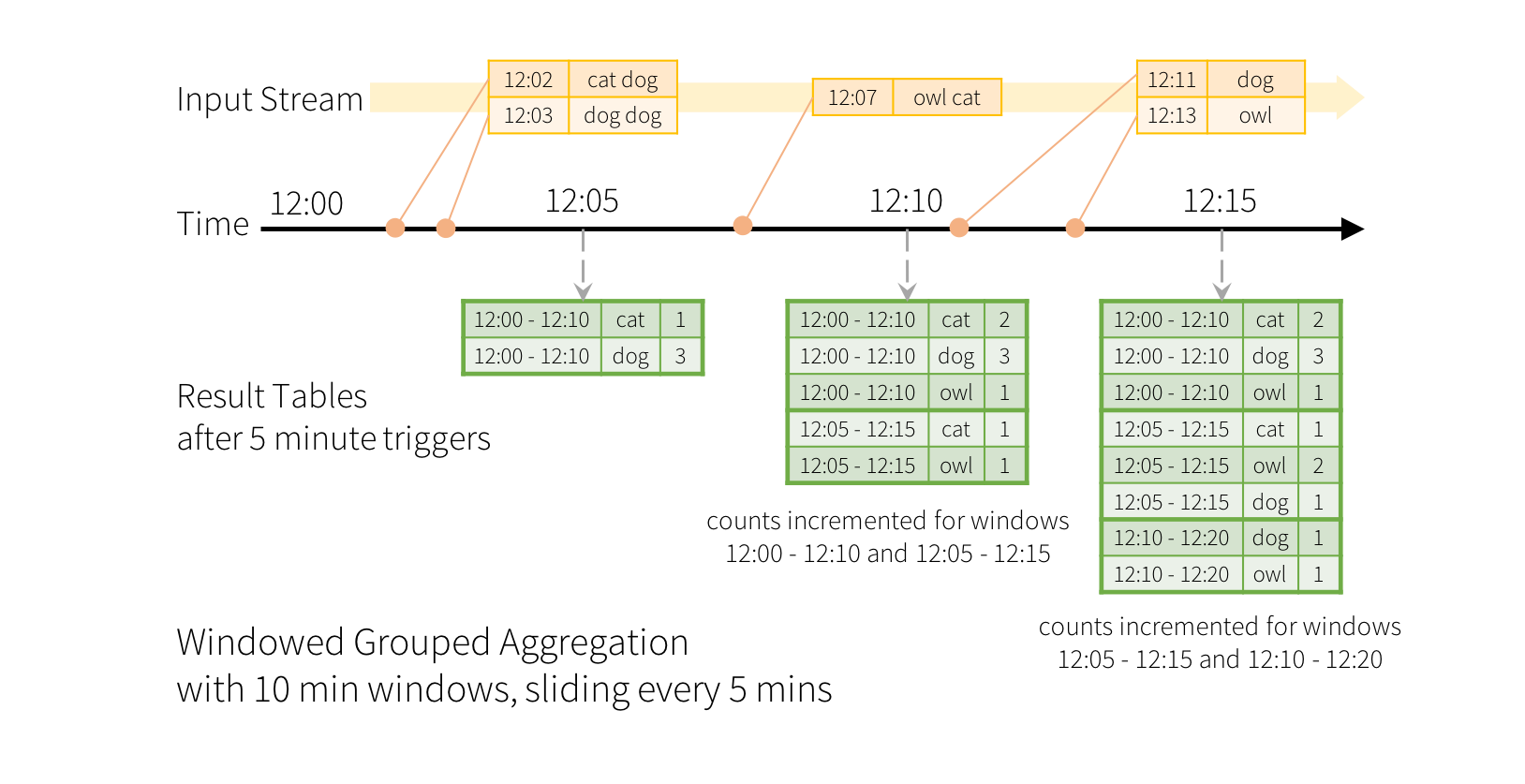{kind=link}
Watermarks¶
There are two relevant times - the time an event is generated (creation time) and the time the event data is received (arrival time). The arrival time may be much later than the creation time for various reasons. Hence windows that define start and end times for events must continue to aggregate data long after the stipulated window period. To avoid excessive use of storage, watermarks can be defined to indicate that events that arrive beyond some threshold will be ignored.
Joining¶
You can join Spark streams to another stream, or to a static DataFrame. For example, you may have a patient with 2 independent sensors (e.g. ECG, HR) as streaming sources, and you want to combine the information.
Source: https://cdn-images-1.medium.com/max/800/1*Qb5RmfVt6XYVYGonYoBiuA.png
Structured Streaming code¶
Streaming DataFrame¶
Streaming does not infer schmea by default, so we read in a single file statically first.
Source¶
[13]:
df = spark.read.json(uri)
[14]:
df.printSchema()
root
|-- Arrival_Time: long (nullable = true)
|-- Creation_Time: long (nullable = true)
|-- Device: string (nullable = true)
|-- Index: long (nullable = true)
|-- Model: string (nullable = true)
|-- User: string (nullable = true)
|-- gt: string (nullable = true)
|-- x: double (nullable = true)
|-- y: double (nullable = true)
|-- z: double (nullable = true)
We fix the schema to use timestamps.
[15]:
from pyspark.sql.types import (
StructType,
StructField,
LongType,
StringType,
TimestampType,
DoubleType
)
[16]:
schema = StructType([
StructField('Arrival_Time',TimestampType(),True),
StructField('Creation_Time',TimestampType(),True),
StructField('Device',StringType(),True),
StructField('Index',LongType(),True),
StructField('Model',StringType(),True),
StructField('User',StringType(),True),
StructField('gt',StringType(),True),
StructField('x',DoubleType(),True),
StructField('y',DoubleType(),True),
StructField('z',DoubleType(),True)]
)
Creating an input stream from files¶
The maxFilesPerTrigger option shown forces the stream to read one file per trigger. This is only used in testing to simulate the arrival of new files.
[17]:
stream = (
spark.readStream.
schema(schema).
option('maxFilesPerTrigger', 1).
json('json/activity-data/')
)
We can operate on the stream almost like a regular DataFrame. Note that we canno simply show the output.
[18]:
counts = stream.groupby('gt').count()
Generating output¶
Here the sink is a table in memory and we must assign the table a name so that it can be queried. We also specify the output mode as complete, which means that it will regenerate the full data frame each time.
[19]:
query = (
counts.writeStream.
queryName('activity_counts_complete').
format('memory').
outputMode('complete').
start()
)
Check that there is an active sgtrem.
[20]:
spark.streams.active
[20]:
[<pyspark.sql.streaming.StreamingQuery at 0x10b4e4a60>]
[21]:
import time
[22]:
time.sleep(60)
Check that the output is being updated.
[23]:
for i in range(3):
spark.sql('''
SELECT * from activity_counts_complete
''').show()
time.sleep(10)
+----------+-----+
| gt|count|
+----------+-----+
| stairsup|20905|
| sit|24619|
| stand|22769|
| walk|26512|
| bike|21593|
|stairsdown|18729|
| null|20896|
+----------+-----+
+----------+-----+
| gt|count|
+----------+-----+
| stairsup|31357|
| sit|36929|
| stand|34154|
| walk|39768|
| bike|32390|
|stairsdown|28094|
| null|31343|
+----------+-----+
+----------+-----+
| gt|count|
+----------+-----+
| stairsup|41809|
| sit|49238|
| stand|45539|
| walk|53024|
| bike|43187|
|stairsdown|37459|
| null|41791|
+----------+-----+
Transformations on streams¶
[24]:
s1 = (
stream.withColumn("stairs", F.expr("gt like '%stairs%'")).
where("stairs").
where("gt is not null").
select("gt", "model", "arrival_time", "creation_time")
)
[25]:
query = (
s1.writeStream.
queryName("transform_example").
format("memory").
outputMode("update").
start()
)
[26]:
time.sleep(60)
[27]:
spark.sql('''
SELECT * FROM transform_example
''').show()
+--------+------+--------------------+--------------------+
| gt| model| arrival_time| creation_time|
+--------+------+--------------------+--------------------+
|stairsup|nexus4|+47116-07-26 02:1...|+47116-07-26 01:4...|
|stairsup|nexus4|+47116-07-26 02:1...|+47116-07-26 01:4...|
|stairsup|nexus4|+47116-07-26 02:1...|+47116-07-26 01:4...|
|stairsup|nexus4|+47116-07-26 02:3...|+47116-07-26 01:5...|
|stairsup|nexus4|+47116-07-26 02:3...|+47116-07-26 01:5...|
|stairsup|nexus4|+47116-07-26 02:4...|+47116-07-26 02:1...|
|stairsup|nexus4|+47116-07-26 02:4...|+47116-07-26 02:1...|
|stairsup|nexus4|+47116-07-26 02:4...|+47116-07-26 02:1...|
|stairsup|nexus4|+47116-07-26 03:0...|+47116-07-26 02:3...|
|stairsup|nexus4|+47116-07-26 03:0...|+47116-07-26 02:3...|
|stairsup|nexus4|+47116-07-26 03:2...|+47116-07-26 02:4...|
|stairsup|nexus4|+47116-07-26 03:2...|+47116-07-26 02:4...|
|stairsup|nexus4|+47116-07-26 03:2...|+47116-08-16 12:0...|
|stairsup|nexus4|+47116-07-26 03:2...|+47116-08-16 12:0...|
|stairsup|nexus4|+47116-07-26 03:3...|+47116-08-16 12:2...|
|stairsup|nexus4|+47116-07-26 03:3...|+47116-08-16 12:2...|
|stairsup|nexus4|+47116-07-26 03:3...|+47116-08-16 12:2...|
|stairsup|nexus4|+47116-07-26 03:3...|+47116-07-26 03:0...|
|stairsup|nexus4|+47116-07-26 03:3...|+47116-08-16 12:2...|
|stairsup|nexus4|+47116-07-26 03:5...|+47116-07-26 03:2...|
+--------+------+--------------------+--------------------+
only showing top 20 rows
[28]:
s2 = (
stream.groupby("gt").mean('x', 'y', 'z')
)
[29]:
query = (
s2.writeStream.
queryName("agg_example").
format("memory").
outputMode("complete").
start()
)
[30]:
time.sleep(60)
[31]:
spark.sql('''
SELECT * FROM agg_example
''').show()
+----------+--------------------+--------------------+--------------------+
| gt| avg(x)| avg(y)| avg(z)|
+----------+--------------------+--------------------+--------------------+
| stairsup|-0.02623301318863...|-0.01385931765291...|-0.09395009728019467|
| sit|-4.92132825379802...|3.757376157445754...|-4.42863346250723E-5|
| stand|-3.00989804137386...|4.133303473120163...|-2.86960196767408...|
| walk|0.001970352086338...|7.489666845955465E-5|-0.00149828380428...|
| bike|0.023512544470933695|-0.01304747996973...|-0.08360475809007037|
|stairsdown|0.028103791071500146|-0.03570080351911368| 0.12203047970606441|
| null|-0.00302501221506...|-0.00410754501410...|0.005961452067049526|
+----------+--------------------+--------------------+--------------------+
Windowed operations with watermarks¶
[32]:
s3 = (
stream.
withWatermark('Creation_Time', '30 minute').
groupBy('User', F.window('Creation_Time', '10 minute', '5 minute')).
count()
)
[33]:
query = (
s3.writeStream.
queryName("windowed_example").
format("memory").
outputMode("complete").
start()
)
[34]:
time.sleep(60)
[35]:
for i in range(3):
spark.sql('''
SELECT * FROM windowed_example
''').show()
time.sleep(10)
+----+------+-----+
|User|window|count|
+----+------+-----+
+----+------+-----+
+----+--------------------+-----+
|User| window|count|
+----+--------------------+-----+
| h|[+47116-12-27 22:...| 2|
| f|[+47119-07-10 13:...| 1|
| d|[+47119-08-09 14:...| 2|
| a|[+47116-12-01 15:...| 4|
| f|[+47119-07-29 01:...| 3|
| b|[+47119-09-14 04:...| 2|
| i|[+47119-06-29 19:...| 4|
| e|[+47119-10-28 23:...| 3|
| d|[+47119-07-21 02:...| 4|
| a|[+47116-11-27 18:...| 3|
| e|[+47119-09-17 09:...| 2|
| f|[+47119-06-23 16:...| 2|
| b|[+47119-09-09 10:...| 4|
| c|[+47116-10-23 23:...| 1|
| c|[+47116-10-20 19:...| 3|
| d|[+47119-08-22 07:...| 3|
| a|[+47116-11-24 23:...| 1|
| g|[+47116-08-19 21:...| 3|
| i|[+47119-05-24 09:...| 2|
| f|[+47119-07-13 10:...| 1|
+----+--------------------+-----+
only showing top 20 rows
+----+--------------------+-----+
|User| window|count|
+----+--------------------+-----+
| f|[+47119-07-10 13:...| 4|
| a|[+47116-12-01 15:...| 7|
| f|[+47119-07-29 01:...| 6|
| i|[+47119-06-29 19:...| 6|
| h|[+47116-12-09 09:...| 4|
| e|[+47119-09-17 09:...| 5|
| b|[+47119-09-09 10:...| 12|
| c|[+47116-10-20 19:...| 4|
| d|[+47119-08-22 07:...| 4|
| a|[+47116-11-24 23:...| 1|
| g|[+47116-08-19 21:...| 5|
| g|[+47116-08-15 01:...| 5|
| d|[+47119-07-25 16:...| 4|
| i|[+47119-05-29 05:...| 5|
| a|[+47116-11-29 07:...| 3|
| c|[+47116-11-05 17:...| 6|
| g|[+47116-07-17 11:...| 6|
| g|[+47116-08-15 13:...| 4|
| e|[+47119-10-12 13:...| 2|
| g|[+47116-07-18 09:...| 4|
+----+--------------------+-----+
only showing top 20 rows
[36]:
# spark.stop()
[ ]: