Understanding the SVD¶
In [2]:
import numpy as np
Singular value decomposition¶
Our goal is to understand the following forms of the SVD.
(1) The matrix A¶
A linear function is one that satisfies the property that
Let \(f(x) = Ax\), where \(A\) is a matrix and \(x\) is a vector. You can check that the matrix \(A\) fulfills the property of being a linear function. If \(A\) is \(m \times n\), then it is a linear map from \(\mathbb{R}^n \mapsto \mathbb{R}^m\).
Let’s consider: what does a matrix do to a vector? Matrix multiplication has a geometric interpretation. When we multiply a vector, we either rotate, reflect, dilate or some combination of those three. So multiplying by a matrix transforms one vector into another vector. This is known as a linear transformation.
Important Facts:
- Any matrix defines a linear transformation
- The matrix form of a linear transformation is NOT unique
- We need only define a transformation by saying what it does to a basis
Suppose we have a matrix \(A\) that defines some transformation. We can take any invertible matrix \(B\) and
defines the same transformation. This operation is called a change of basis, because we are simply expressing the transformation with respect to a different basis.
Example
Let \(f(x)\) be the linear transformation that takes \(e_1=(1,0)\) to \(f(e_1)=(2,3)\) and \(e_2=(0,1)\) to \(f(e_2) = (1,1)\). A matrix representation of \(f\) would be given by:
This is the matrix we use if we consider the vectors of \(\mathbb{R}^2\) to be linear combinations of the form
Now, consider a second pair of (linearly independent) vectors in \(\mathbb{R}^2\), say \(v_1=(1,3)\) and \(v_2=(4,1)\). We first find the transformation that takes \(e_1\) to \(v_1\) and \(e_2\) to \(v_2\). A matrix representation for this is:
Our original transformation \(f\) can be expressed with respect to the basis \(v_1, v_2\) via
- Span and basis
- Inner and outer products of vectors
- Rank of outer product is 1
- \(C(A)\), \(N(A)\), \((C(A^T))\) and \(N(A^T)\) mean
- Dimensions of each space and its rank
- How to find a basis for each subspace given a \(m \times n\) matrix \(A\)
- Sketch the diagram relating the four fundamental subspaces
(2) Orthogonal matrices \(U\) and \(V^T\)¶
Orthogonal (perpendicular) vectors
Orthonormal vectors
Orthogonal matrix
\(Q^TQ = QQ^T = I\)
Orthogonal matrices are rotations (and reflections)
Orthogonal matrices preserve norms (lengths)
2D orthogonal matrix is a rotation matrix
\[\begin{split} V = \begin{bmatrix} \cos\theta & -\sin \theta \\ \sin \theta & \cos \theta \end{bmatrix}\end{split}\]\(V^T\) rotates the perpendicular frame spanned by \(V\) into the standard frame spanned by \(e_i\)
\(V\) rotates the standard frame into the frame spanned by \(V\)
- \[\text{proj}_v x = \frac{\langle x, v \rangle}{\langle v, v \rangle} v\]
Matrix form
\[P = \frac{vv^T}{v^Tv}\]Gram-Schmidt for converting \(A\) into an orthogonal matrix \(Q\)
QR decomposition
(3) Diagonal matrix \(S\)¶
Recall that a matrix \(A\) is a transform with respect to some basis
It is desirable to find the simplest similar matrix \(B\) in some other basis
\(A\) and \(B\) represent the exact same linear transform, just in different coordinate systems
\(Av = \lambda v\) defines the eigenvectors and eigenvalues of \(A\)
When a square matrix \(A\) is real, symmetric and has all non-negative eigenvalues, it has an eigen-space decomposition (ESD)
\[ \begin{align}\begin{aligned} A = V \Lambda V^T\\where :math:`V` is orthogonal and :math:`\Lambda` is diagonal\end{aligned}\end{align} \]The columns of \(V\) are formed from the eigenvectors of \(A\)
The diagonals of \(\Lambda\) are the eigenvalues of \(A\) (arrange from large to small in absolute value)
(4) SVD \(U\Sigma V^T\)¶
The SVD is a generalization of ESD for general \(m \times n\) matrices \(A\)
If \(A\) is \((m \times n)\), we cannot perform an ESD
\(A^TA\) is diagonalizable (note this is the dot product of all pairs of column vectors in \(A\))
- \[A^TA = V \Lambda V^T\]
Let \(\Lambda = \Sigma^2\)
Let \(U = AV\Sigma^{-1}\)
The \(A = U\Sigma V^T\)
Show \(U\) is orthogonal
Show \(U\) is formed from eigenvectors of \(AA^T\)
Geometric interpretation of SVD
- rotate orthogonal frame \(V\) onto standard frame
- scale by \(\Sigma\)
- rotate standard frame into orthogonal frame \(U\)
Covariance, PCA and SVD¶
Remember the formula for covariance
where \(\text{Cov}(X, X)\) is the sample variance of \(X\).
In [14]:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import scipy.linalg as la
In [24]:
np.set_printoptions(precision=3)
In [25]:
def cov(x, y):
"""Returns covariance of vectors x and y)."""
xbar = x.mean()
ybar = y.mean()
return np.sum((x - xbar)*(y - ybar))/(len(x) - 1)
In [26]:
X = np.random.random(10)
Y = np.random.random(10)
In [27]:
np.array([[cov(X, X), cov(X, Y)], [cov(Y, X), cov(Y,Y)]])
Out[27]:
array([[0.077, 0.027],
[0.027, 0.097]])
Using numpy function
In [28]:
np.cov(X, Y)
Out[28]:
array([[0.077, 0.027],
[0.027, 0.097]])
In [29]:
Z = np.random.random(10)
np.cov([X, Y, Z])
Out[29]:
array([[0.077, 0.027, 0.01 ],
[0.027, 0.097, 0.014],
[0.01 , 0.014, 0.06 ]])
In [30]:
mu = [0,0]
sigma = [[0.6,0.2],[0.2,0.2]]
n = 1000
x = np.random.multivariate_normal(mu, sigma, n).T
In [31]:
A = np.cov(x)
In [32]:
m = np.array([[1,2,3],[6,5,4]])
ms = m - m.mean(1).reshape(2,1)
np.dot(ms, ms.T)/2
Out[32]:
array([[ 1., -1.],
[-1., 1.]])
In [33]:
e, v = la.eigh(A)
In [34]:
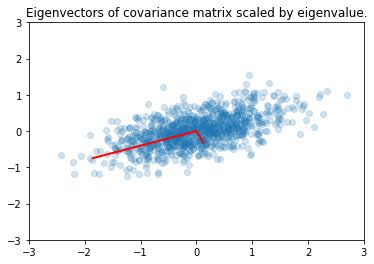
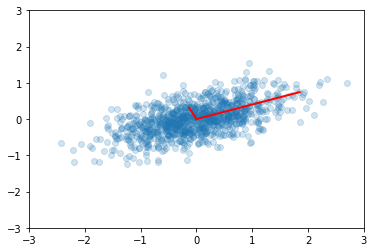
plt.scatter(x[0,:], x[1,:], alpha=0.2)
for e_, v_ in zip(e, v.T):
plt.plot([0, 3*e_*v_[0]], [0, 3*e_*v_[1]], 'r-', lw=2)
plt.axis([-3,3,-3,3])
plt.title('Eigenvectors of covariance matrix scaled by eigenvalue.');
PCA¶
Principal Components Analysis (PCA) basically means to find and rank all the eigenvalues and eigenvectors of a covariance matrix. This is useful because high-dimensional data (with \(p\) features) may have nearly all their variation in a small number of dimensions \(k\), i.e. in the subspace spanned by the eigenvectors of the covariance matrix that have the \(k\) largest eigenvalues. If we project the original data into this subspace, we can have a dimension reduction (from \(p\) to \(k\)) with hopefully little loss of information.
Numerically, PCA is typically done using SVD on the data matrix rather than eigendecomposition on the covariance matrix. The next section explains why this works. Numerically, the condition number for working with the covariance matrix directly is the square of the condition number using SVD, so SVD minimizes errors.
For zero-centered vectors,
and so the covariance matrix for a data set X that has zero mean in each feature vector is just \(XX^T/(n-1)\).
In other words, we can also get the eigendecomposition of the covariance matrix from the positive semi-definite matrix \(XX^T\).
Note: Here \(x\) is a matrix of row vectors
In [35]:
X = np.random.random((5,4))
X
Out[35]:
array([[0.027, 0.212, 0.602, 0.276],
[0.118, 0.095, 0.058, 0.736],
[0.595, 0.283, 0.537, 0.475],
[0.39 , 0.952, 0.45 , 0.16 ],
[0.493, 0.958, 0.811, 0.184]])
In [36]:
Y = X - X.mean(1)[:, None]
In [40]:
np.around(Y.mean(1), 5)
Out[40]:
array([-0., 0., -0., -0., -0.])
In [41]:
Y
Out[41]:
array([[-0.252, -0.067, 0.323, -0.003],
[-0.134, -0.157, -0.194, 0.484],
[ 0.123, -0.19 , 0.064, 0.003],
[-0.098, 0.464, -0.038, -0.328],
[-0.119, 0.346, 0.2 , -0.427]])
In [42]:
np.cov(X)
Out[42]:
array([[ 0.057, -0.007, 0.001, -0.006, 0.024],
[-0.007, 0.105, 0.001, -0.07 , -0.095],
[ 0.001, 0.001, 0.018, -0.034, -0.023],
[-0.006, -0.07 , -0.034, 0.111, 0.102],
[ 0.024, -0.095, -0.023, 0.102, 0.119]])
In [43]:
np.cov(Y)
Out[43]:
array([[ 0.057, -0.007, 0.001, -0.006, 0.024],
[-0.007, 0.105, 0.001, -0.07 , -0.095],
[ 0.001, 0.001, 0.018, -0.034, -0.023],
[-0.006, -0.07 , -0.034, 0.111, 0.102],
[ 0.024, -0.095, -0.023, 0.102, 0.119]])
In [44]:
e1, v1 = np.linalg.eig(np.dot(x, x.T)/(n-1))
In [45]:
plt.scatter(x[0,:], x[1,:], alpha=0.2)
for e_, v_ in zip(e1, v1.T):
plt.plot([0, 3*e_*v_[0]], [0, 3*e_*v_[1]], 'r-', lw=2)
plt.axis([-3,3,-3,3]);
Change of basis¶
Suppose we have a vector \(u\) in the standard basis \(B\) , and a matrix \(A\) that maps \(u\) to \(v\), also in \(B\). We can use the eigenvalues of \(A\) to form a new basis \(B'\). As explained above, to bring a vector \(u\) from \(B\)-space to a vector \(u'\) in \(B'\)-space, we multiply it by \(Q^{-1}\), the inverse of the matrix having the eigenvctors as column vectors. Now, in the eigenvector basis, the equivalent operation to \(A\) is the diagonal matrix \(\Lambda\) - this takes \(u'\) to \(v'\). Finally, we convert \(v'\) back to a vector \(v\) in the standard basis by multiplying with \(Q\).
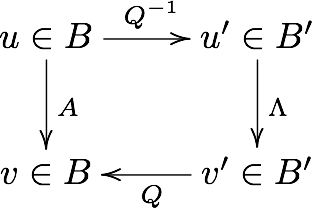
Commuative diagram
Rotate to standard frame¶
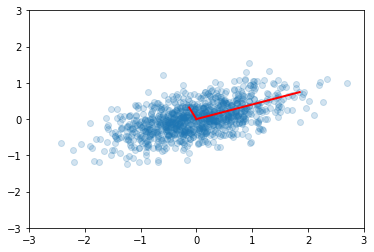
In [46]:
ys = np.dot(v1.T, x)
Principal components are simply the eigenvectors of the covariance matrix used as basis vectors. Each of the original data points is expressed as a linear combination of the principal components, giving rise to a new set of coordinates.
In [47]:
plt.scatter(ys[0,:], ys[1,:], alpha=0.2)
for e_, v_ in zip(e1, np.eye(2)):
plt.plot([0, 3*e_*v_[0]], [0, 3*e_*v_[1]], 'r-', lw=2)
plt.axis([-3,3,-3,3]);
For example, if we only use the first column of ys, we will have the
projection of the data onto the first principal component, capturing the
majority of the variance in the data with a single feature that is a
linear combination of the original features.
We may need to transform the (reduced) data set to the original feature coordinates for interpretation. This is simply another linear transform (matrix multiplication).
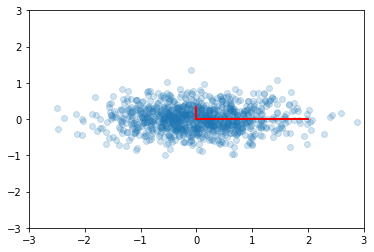
In [48]:
zs = np.dot(v1, ys)
In [49]:
plt.scatter(zs[0,:], zs[1,:], alpha=0.2)
for e_, v_ in zip(e1, v1.T):
plt.plot([0, 3*e_*v_[0]], [0, 3*e_*v_[1]], 'r-', lw=2)
plt.axis([-3,3,-3,3]);
In [50]:
u, s, v = np.linalg.svd(x)
u.dot(u.T)
Out[50]:
array([[1.00e+00, 1.11e-16],
[1.11e-16, 1.00e+00]])
We have the spectral decomposition of the covariance matrix
Suppose \(\Lambda\) is a rank \(p\) matrix. To reduce the dimensionality to \(k \le p\), we simply set all but the first \(k\) values of the diagonal of \(\Lambda\) to zero. This is equivalent to ignoring all except the first \(k\) principal components.
What does this achieve? Recall that \(A\) is a covariance matrix, and the trace of the matrix is the overall variability, since it is the sum of the variances.
In [51]:
A
Out[51]:
array([[0.589, 0.191],
[0.191, 0.191]])
In [52]:
A.trace()
Out[52]:
0.7798589520198774
In [54]:
e, v = np.linalg.eigh(A)
D = np.diag(e)
D
Out[54]:
array([[0.114, 0. ],
[0. , 0.665]])
In [55]:
D.trace()
Out[55]:
0.7798589520198773
In [56]:
D[0,0]/D.trace()
Out[56]:
0.14677219641978512
Since the trace is invariant under change of basis, the total variability is also unchanged by PCA. By keeping only the first \(k\) principal components, we can still “explain” \(\sum_{i=1}^k e[i]/\sum{e}\) of the total variability. Sometimes, the degree of dimension reduction is specified as keeping enough principal components so that (say) \(90\%\) of the total variability is explained.
Using SVD for PCA¶
SVD is a decomposition of the data matrix \(X = U S V^T\) where \(U\) and \(V\) are orthogonal matrices and \(S\) is a diagonal matrix.
Recall that the transpose of an orthogonal matrix is also its inverse, so if we multiply on the right by \(X^T\), we get the following simplification
Compare with the eigendecomposition of a matrix \(A = W \Lambda W^{-1}\), we see that SVD gives us the eigendecomposition of the matrix \(XX^T\), which as we have just seen, is basically a scaled version of the covariance for a data matrix with zero mean, with the eigenvectors given by \(U\) and eigenvealuse by \(S^2\) (scaled by \(n-1\))..
In [57]:
u, s, v = np.linalg.svd(x)
In [58]:
e2 = s**2/(n-1)
v2 = u
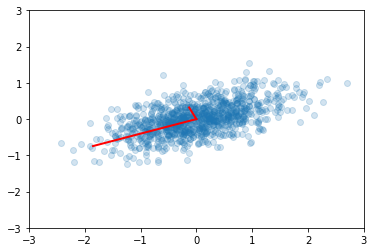
plt.scatter(x[0,:], x[1,:], alpha=0.2)
for e_, v_ in zip(e2, v2):
plt.plot([0, 3*e_*v_[0]], [0, 3*e_*v_[1]], 'r-', lw=2)
plt.axis([-3,3,-3,3]);
In [59]:
v1 # from eigenvectors of covariance matrix
Out[59]:
array([[ 0.928, -0.373],
[ 0.373, 0.928]])
In [62]:
v2 # from SVD
Out[62]:
array([[-0.928, -0.373],
[-0.373, 0.928]])
In [63]:
e1 # from eigenvalues of covariance matrix
Out[63]:
array([0.665, 0.115])
In [64]:
e2 # from SVD
Out[64]:
array([0.665, 0.115])