Introduction to Spark¶
This lecture is an introduction to the Spark framework for distributed computing, the basic data and control flow abstractions, and getting comfortable with the functional programming style needed to write a Spark application.
- What problem does Spark solve?
- SparkContext and the master configuration
- RDDs
- Actions
- Transforms
- Key-value RDDs
- Example - word count
- Persistence
- Merging key-value RDDs
Learning objectives¶
- Overview of Spark
- Working with Spark RDDs
- Actions and transforms
- Working with Spark DataFrames
- Using the
mlandmllibfor machine learning
Not covered¶
- Spark GraphX (library for graph algorithms)
- Spark Streaming (library for streaming (microbatch) data)
Installation¶
You should use the current version of Spark at
https://spark.apache.org/downloads.html. Choose the package
Pre-built for Hadoop2.7 and later. The instructions below use the
version current as of 9 April 2018.
cd ~
wget https://www.apache.org/dyn/closer.lua/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz
tar spark-2.3.0-bin-hadoop2.7.tgz
rm spark-2.3.0-bin-hadoop2.7.tgz
mv spark-2.3.0-bin-hadoop2.7 spark
Install the py4j Python package needed for pyspark
pip install py4j
You need to define these environment variables before starting the notebook.
export SPARK_HOME=~/spark
export PYSPARK_PYTHON=python3
export PYTHONPATH=$SPARK_HOME/python/:$PYTHONPATH
export PYSPARK_SUBMIT_ARGS="--packages ${PACKAGES} pyspark-shell"
In Unix/Mac, this can be done in .bashrc or .bash_profile.
For the adventurous, see Running Spark on an AWS EMR cluster.
Overview of Spark¶
With massive data, we need to load, extract, transform and analyze the data on multiple computers to overcome I/O and processing bottlenecks. However, when working on multiple computers (possibly hundreds to thousands), there is a high risk of failure in one or more nodes. Distributed computing frameworks are designed to handle failures gracefully, allowing the developer to focus on algorithm development rather than system administration.
The first such widely used open source framework was the Hadoop MapReduce framework. This provided transparent fault tolerance, and popularized the functional programming approach to distributed computing. The Hadoop work-flow uses repeated invocations of the following instructions:
load dataset from disk to memory
map function to elements of dataset
reduce results of map to get new aggregate dataset
save new dataset to disk
Hadoop has two main limitations:
- the repeated saving and loading of data to disk can be slow, and makes interactive development very challenging
- restriction to only
mapandreduceconstructs results in increased code complexity, since every problem must be tailored to themap-reduceformat
Spark is a more recent framework for distributed computing that addresses the limitations of Hadoop by allowing the use of in-memory datasets for iterative computation, and providing a rich set of functional programming constructs to make the developer’s job easier. Spark also provides libraries for common big data tasks, such as the need to run SQL queries, perform machine learning and process large graphical structures.
Distributed computing bakkground¶
With distributed computing, you interact with a network of computers that communicate via message passing as if issuing instructions to a single computer.

Distributed computing
{kind=link}
- There are 3 major components to a distributed system
- storage
- cluster management
- computing engine
- Hadoop is a framework that provides all 3
- distributed storage (HDFS)
- clsuter managemnet (YARN)
- computing eneine (MapReduce)
- Spakr only provides the (in-memory) distributed computing engine, and relies on other frameworks for storage and clsuter manageemnt. It is most frequently used on top of the Hadoop framework, but can also use other distribtued storage(e.g. S3 and Cassandra) or cluster mangement (e.g. Mesos) software.
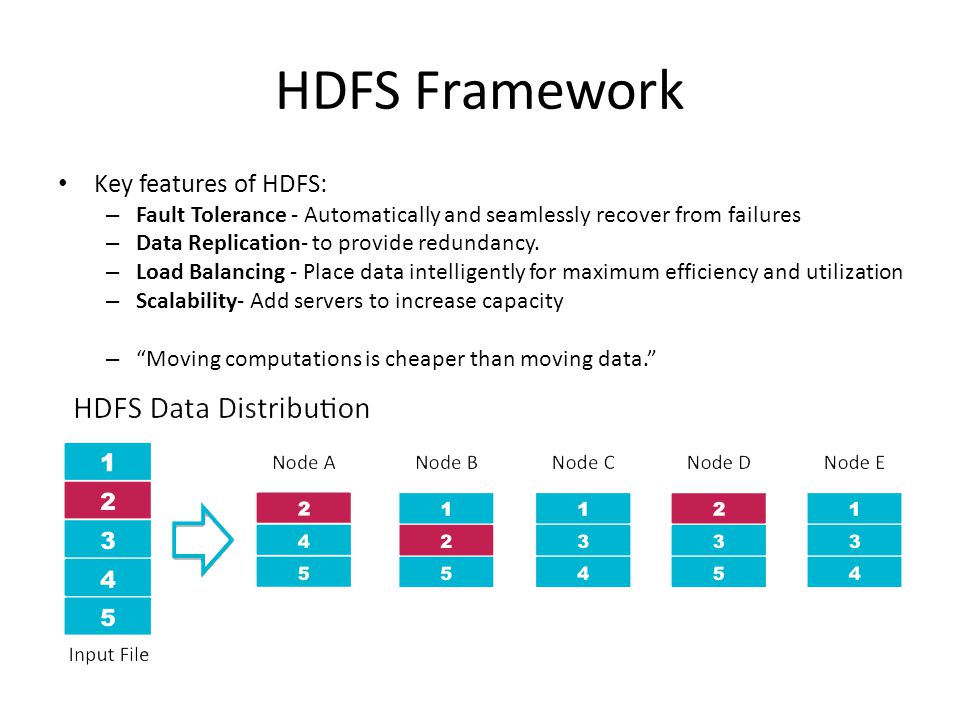
storage
Source: http://slideplayer.com/slide/3406872/12/images/15/HDFS+Framework+Key+features+of+HDFS:.jpg
- Resource manageer (manages cluster resources)
- Scheduler
- Applicaitons manager
- Ndoe manager (manages single machine/node)
- manages data containers/partitions
- monitors reosurce usage
- reprots to resource manager

Yarn
Source: https://kannandreams.files.wordpress.com/2013/11/yarn1.png

yarn ops
Source: https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/yarn_architecture.gif
Spark has several advantages over Hadoop MapReduce
- Use of RAM rahter than disk mean fsater processing for multi-step operations
- Allows interactive applicaitons
- Allows real-time applications
- More flexible programming API (full range of functional constructs)

Hadoop
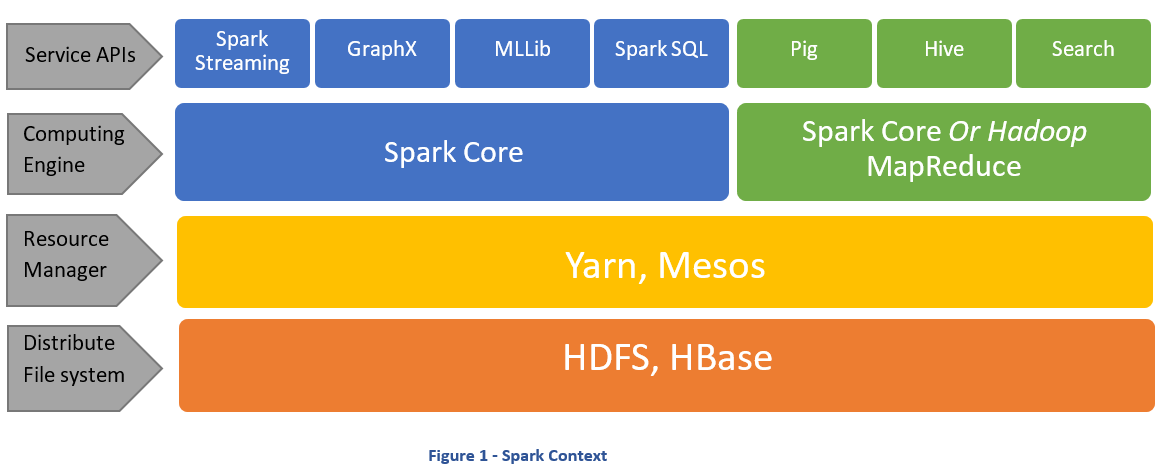
spark
Source: https://cdn-images-1.medium.com/max/1165/1*z0Vm749Pu6mHdlyPsznMRg.png
- Spark is written in Scala, a functional programming language built on top of the Java Virtual Machine (JVM)
- Traditionally, you have to code in Scala to get the best performacne from Spark
- With Spark DataFrames and vectorized operations (Spark 2.3 onwards) Python is now competitive

eco
Source: https://data-flair.training/blogs/wp-content/uploads/apache-spark-ecosystem-components.jpg
- Livy provides a REST interface to a Spark cluster.
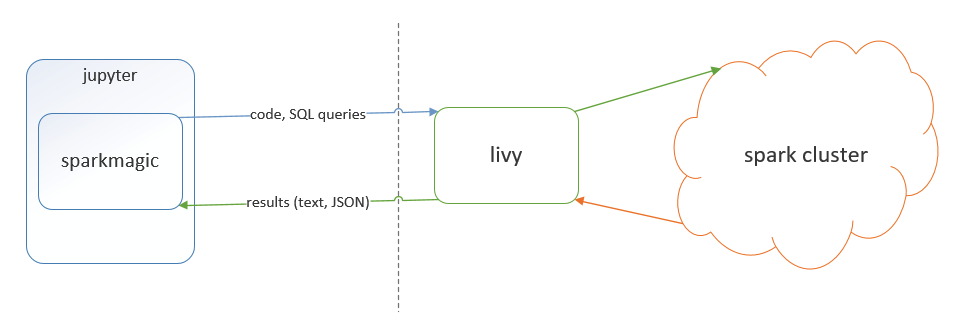
Livy
Source: https://cdn-images-1.medium.com/max/956/0*-lwKpnEq0Tpi3Tlj.png

PySpark
Source: http://i.imgur.com/YlI8AqEl.png

rdd
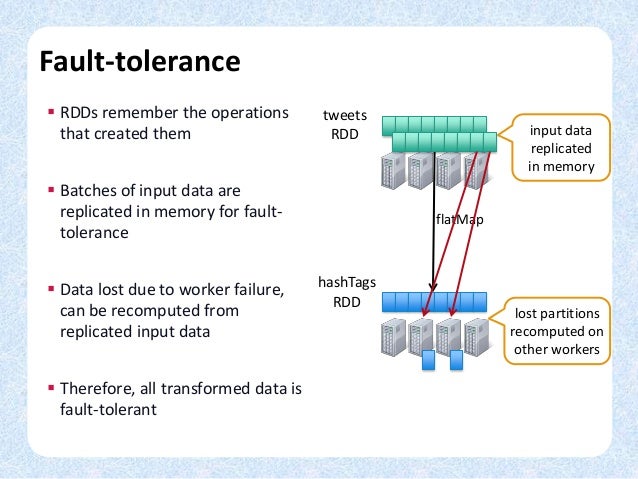
graph
In [1]:
%%spark
Starting Spark application
SparkSession available as 'spark'.
In [2]:
%%info
Note the proxyUser from %%info.
In [2]:
%%configure -f
{"driverMemory": "2G",
"numExecutors": 10,
"executorCores": 2,
"executorMemory": "2048M",
"proxyUser": "user06021",
"conf": {"spark.master": "yarn"}}
Starting Spark application
SparkSession available as 'spark'.
The default version of Python with the PySpark kernel is Python 2.
In [4]:
import sys
sys.version_info
sys.version_info(major=2, minor=7, micro=12, releaselevel='final', serial=0)
When you are done running Sark jobs with this notebook, go to the notebook’s file menu, and select the “Close and Halt” option to terminate the notebook’s kernel and clear the Spark session.