Architecture of a Spark Application¶
Big picture¶
You will type your commands iin a local Spark session, and the SparkContext will take care of running your instructions distributed across the workers (executors) on a cluster. Each executor can have 1 or more CPU cores, its own memory cahe, and is responsible for handling its own distributed tasks. Communicaiton between local and workers and between worker and worker is handled by a cluster manager.

Spark components
Source: http://spark.apache.org/docs/latest/img/cluster-overview.png
Organizaiton of Spark tasks¶
Spark organizes tasks that can be performed without exchanging data across partitions into stages. The sequecne of tasks to be perfomed are laid out as a Directed Acyclic Graph (DAG). Tasks are differenitated into transforms (lazy evalutation - just add to DAG) and actions (eager evaluation - execute the specified path in the DAG). Note that calculations are not cached unless requested. Hence if you have triggered the action after RDD3 in the figure, then trigger the aciton after RDD6, RDD2 will be re-generated from RDD1 twice. We can avoid the re-calculation by persisting or cacheing RDD2.
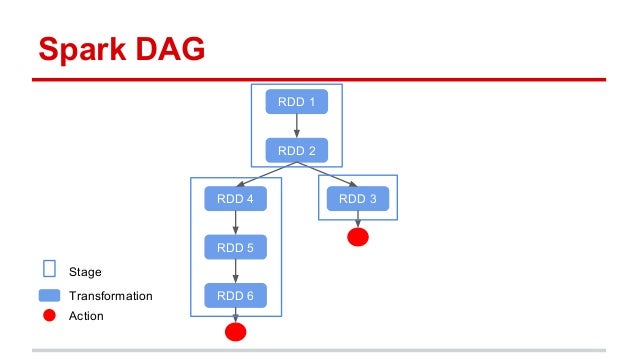
Spark stages
SparkContext¶
A SparkContext represents the connection to a Spark cluster, and can be
used to create RDDs, accumulators and broadcast variables on that
cluster. Here we set it up to use local nodes - the argument
locals[*] means to use the local machine as the cluster, using as
many worker threads as there are cores. You can also explicitly set the
number of cores with locals[k] where k is an integer.
With Saprk 2.0 onwards, there is also a SparkSession that manages DataFrames, which is the preferred abstraction for working in Spark. However DataFrames are composed of RDDs, and it is still necesaary to understand how to use and mainpulate RDDs for low level operations.
Depending on your setup, you many have to import SparkContext. This is
not necessary in our Docker containers as we will be using livy.
from pyspark import SparkContext
sc = SparkContext(master = 'local[*]')
Start spark
In [1]:
%%spark
Starting Spark application
SparkSession available as 'spark'.
In [112]:
import numpy as np
Version
In [113]:
spark.version
u'2.2.0.2.6.3.0-235'
Number of workers
In [114]:
sc.defaultParallelism
4
Data in an RDD is distributed across partitions. It is most efficient if data does not have to be transferred across partitions. We can see the default minimumn number of partitions, and the actual number in an RDD later.
In [115]:
sc.defaultMinPartitions
2
Resilient Distributed Datasets (RDD)¶
Creating an RDD¶
The RDD (Resilient Distributed Dataset) is a data storage abstraction - you can work with it as though it were single unit, while it may actually be distributed over many nodes in the computing cluster.
A first example¶
Distribute the data set to the workers
In [116]:
xs = sc.parallelize(range(10))
xs
ParallelCollectionRDD[133] at parallelize at PythonRDD.scala:480
In [117]:
xs.getNumPartitions()
4
Return all data within each partition as a list. Note that the glom() operation operates on the distributed workers without centralizing the data.
In [118]:
xs.glom().collect()
[[0, 1], [2, 3], [4, 5], [6, 7, 8, 9]]
Only keep even numbers
In [119]:
xs = xs.filter(lambda x: x % 2 == 0)
xs
PythonRDD[135] at RDD at PythonRDD.scala:48
Square all elements
In [120]:
xs = xs.map(lambda x: x**2)
xs
PythonRDD[136] at RDD at PythonRDD.scala:48
Execute the code and return the final dataset
In [121]:
xs.collect()
[0, 4, 16, 36, 64]
Reduce also triggers a calculation
In [122]:
xs.reduce(lambda x, y: x+y)
120
A common Spark idiom chains mutiple functions together¶
In [123]:
(
sc.parallelize(range(10))
.filter(lambda x: x % 2 == 0)
.map(lambda x: x**2)
.collect()
)
[0, 4, 16, 36, 64]
Actions and transforms¶
A transform maps an RDD to another RDD - it is a lazy operation. To actually perform any work, we need to apply an action.
Actions¶
In [124]:
x = sc.parallelize(np.random.randint(1, 6, 10))
In [125]:
x.collect()
[3, 3, 4, 2, 5, 4, 3, 4, 1, 1]
In [126]:
x.take(5)
[3, 3, 4, 2, 5]
In [127]:
x.first()
3
In [128]:
x.top(5)
[5, 4, 4, 4, 3]
In [129]:
x.takeSample(True, 15)
[4, 3, 4, 3, 1, 3, 1, 3, 3, 3, 1, 5, 2, 4, 1]
In [130]:
x.count()
10
In [131]:
x.distinct().collect()
[4, 1, 5, 2, 3]
In [132]:
x.countByValue()
defaultdict(<type 'int'>, {1: 2, 2: 1, 3: 3, 4: 3, 5: 1})
In [133]:
x.sum()
30
In [134]:
x.max()
5
In [135]:
x.mean()
3.0
In [136]:
x.stats()
(count: 10, mean: 3.0, stdev: 1.26491106407, max: 5.0, min: 1.0)
Reduce, fold and aggregate actions¶
From the API:
reduce(f)
Reduces the elements of this RDD using the specified commutative and associative binary operator. Currently reduces partitions locally.
fold(zeroValue, op)
Aggregate the elements of each partition, and then the results for all the partitions, using a given associative function and a neutral “zero value.”
The function op(t1, t2) is allowed to modify t1 and return it as its result value to avoid object allocation; however, it should not modify t2.
This behaves somewhat differently from fold operations implemented for non-distributed collections in functional languages like Scala. This fold operation may be applied to partitions individually, and then fold those results into the final result, rather than apply the fold to each element sequentially in some defined ordering. For functions that are not commutative, the result may differ from that of a fold applied to a non-distributed collection.
aggregate(zeroValue, seqOp, combOp)
Aggregate the elements of each partition, and then the results for all the partitions, using a given combine functions and a neutral “zero value.”
The functions op(t1, t2) is allowed to modify t1 and return it as its result value to avoid object allocation; however, it should not modify t2.
The first function (seqOp) can return a different result type, U, than the type of this RDD. Thus, we need one operation for merging a T into an U and one operation for merging two U
Notes:
- All 3 operations take a binary op with signature op(accumulator, operand)
In [137]:
x = sc.parallelize(np.random.randint(1, 10, 12))
In [138]:
x.collect()
[7, 1, 1, 9, 1, 4, 5, 3, 2, 7, 5, 9]
max using reduce
In [139]:
x.reduce(lambda x, y: x if x > y else y)
9
sum using reduce
In [140]:
x.reduce(lambda x, y: x+y)
54
sum using fold
In [141]:
x.fold(0, lambda x, y: x+y)
54
prod using reduce
In [142]:
x.reduce(lambda x, y: x*y)
2381400
prod using fold
In [143]:
x.fold(1, lambda x, y: x*y)
2381400
sum using aggregate
In [144]:
x.aggregate(0, lambda x, y: x + y, lambda x, y: x + y)
54
count using aggregate
In [145]:
x.aggregate(0, lambda acc, _: acc + 1, lambda x, y: x+y)
12
mean using aggregate
In [146]:
sum_count = x.aggregate([0,0],
lambda acc, x: (acc[0]+x, acc[1]+1),
lambda acc1, acc2: (acc1[0] + acc2[0], acc1[1]+ acc2[1]))
sum_count[0]/sum_count[1]
4
Warning: Be very careful wiht fold and aggregate - the zero value must be “neutral”. The behhavior can be different from Python’s reduce with an initial value.
In [147]:
xs = x.collect()
In [148]:
xs = np.array(xs)
Exercise: Explain the results shown below:
In [149]:
from functools import reduce
In [150]:
reduce(lambda x, y: x + y, xs, 1)
55
In [151]:
x.fold(1, lambda acc, val: acc + val)
59
In [152]:
x.aggregate(1, lambda x, y: x + y, lambda x, y: x + y)
59
Exercise: Explain the results shown below:
In [153]:
reduce(lambda x, y: x + y**2, xs, 0)
342
In [154]:
np.sum(xs**2)
342
In [155]:
x.fold(0, lambda x, y: x + y**2)
37674
In [156]:
x.aggregate(0, lambda x, y: x + y**2, lambda x, y: x + y)
342
Exercise: Explain the results shown belwo:
In [157]:
x.fold([], lambda acc, val: acc + [val])
[[7, 1, 1], [9, 1, 4], [5, 3, 2], [7, 5, 9]]
In [158]:
seqOp = lambda acc, val: acc + [val]
combOp = lambda acc, val: acc + val
x.aggregate([], seqOp, combOp)
[7, 1, 1, 9, 1, 4, 5, 3, 2, 7, 5, 9]
Transforms¶
In [159]:
x = sc.parallelize([1,2,3,4])
y = sc.parallelize([3,3,4,6])
In [160]:
x.map(lambda x: x + 1).collect()
[2, 3, 4, 5]
In [161]:
x.filter(lambda x: x%3 == 0).collect()
[3]
Think of flatMap as a map followed by a flatten operation¶
In [162]:
x.flatMap(lambda x: range(x-2, x)).collect()
[-1, 0, 0, 1, 1, 2, 2, 3]
In [163]:
x.sample(False, 0.5).collect()
[2]
Set-like transformss¶
In [164]:
y.distinct().collect()
[4, 6, 3]
In [165]:
x.union(y).collect()
[1, 2, 3, 4, 3, 3, 4, 6]
In [166]:
x.intersection(y).collect()
[3, 4]
In [167]:
x.subtract(y).collect()
[1, 2]
In [168]:
x.cartesian(y).collect()
[(1, 3), (1, 3), (1, 4), (1, 6), (2, 3), (2, 3), (2, 4), (2, 6), (3, 3), (3, 3), (3, 4), (3, 6), (4, 3), (4, 3), (4, 4), (4, 6)]
Note that flatmap gets rid of empty lists, and is a good way to ignore “missing” or “malformed” entires.
In [169]:
def conv(x):
try:
return [float(x)]
except:
return []
In [170]:
s = "Thee square root of 3 is less than 3.14 unless you divide by 0".split()
x = sc.parallelize(s)
x.collect()
['Thee', 'square', 'root', 'of', '3', 'is', 'less', 'than', '3.14', 'unless', 'you', 'divide', 'by', '0']
In [171]:
x.map(conv).collect()
[[], [], [], [], [3.0], [], [], [], [3.14], [], [], [], [], [0.0]]
In [172]:
x.flatMap(conv).collect()
[3.0, 3.14, 0.0]
Working with key-value pairs¶
RDDs consissting of key-value pairs are required for many Spark operatinos. They can be created by using a function that returns an RDD composed of tuples.
In [173]:
data = [('ann', 'spring', 'math', 98),
('ann', 'fall', 'bio', 50),
('bob', 'spring', 'stats', 100),
('bob', 'fall', 'stats', 92),
('bob', 'summer', 'stats', 100),
('charles', 'spring', 'stats', 88),
('charles', 'fall', 'bio', 100)
]
In [174]:
rdd = sc.parallelize(data)
In [175]:
rdd.keys().collect()
['ann', 'ann', 'bob', 'bob', 'bob', 'charles', 'charles']
In [176]:
rdd.collect()
[('ann', 'spring', 'math', 98), ('ann', 'fall', 'bio', 50), ('bob', 'spring', 'stats', 100), ('bob', 'fall', 'stats', 92), ('bob', 'summer', 'stats', 100), ('charles', 'spring', 'stats', 88), ('charles', 'fall', 'bio', 100)]
Sum values by key
In [177]:
(
rdd.
map(lambda x: (x[0], x[3])).
reduceByKey(lambda x, y: x + y).
collect()
)
[('ann', 148), ('bob', 292), ('charles', 188)]
Running list of values by key
In [178]:
(
rdd.
map(lambda x: ((x[0], x[3]))).
aggregateByKey([], lambda x, y: x + [y], lambda x, y: x + y).
collect()
)
[('ann', [98, 50]), ('bob', [92, 100, 100]), ('charles', [88, 100])]
Average by key
In [179]:
(
rdd.
map(lambda x: ((x[0], x[3]))).
aggregateByKey([], lambda x, y: x + [y], lambda x, y: x + y).
map(lambda x: (x[0], sum(x[1])/len(x[1]))).
collect()
)
[('ann', 74), ('bob', 97), ('charles', 94)]
Using a different key
In [180]:
(
rdd.
map(lambda x: ((x[2], x[3]))).
aggregateByKey([], lambda x, y: x + [y], lambda x, y: x + y).
map(lambda x: (x[0], sum(x[1])/len(x[1]))).
collect()
)
[('stats', 95), ('bio', 75), ('math', 98)]
Using key-value pairs to find most frequent words in Ulysses¶
In [181]:
hadoop = sc._jvm.org.apache.hadoop
fs = hadoop.fs.FileSystem
conf = hadoop.conf.Configuration()
path = hadoop.fs.Path('/data/texts')
for f in fs.get(conf).listStatus(path):
print f.getPath()
hdfs://vcm-2167.oit.duke.edu:8020/data/texts/Portrait.txt
hdfs://vcm-2167.oit.duke.edu:8020/data/texts/Ulysses.txt
In [182]:
ulysses = sc.textFile('/data/texts/Portrait.txt')
In [183]:
ulysses.take(10)
[u'', u"Project Gutenberg's A Portrait of the Artist as a Young Man, by James", u'Joyce', u'', u'This eBook is for the use of anyone anywhere at no cost and with almost', u'no restrictions whatsoever. You may copy it, give it away or re-use it', u'under the terms of the Project Gutenberg License included with this', u'eBook or online at www.gutenberg.net', u'', u'']
In [184]:
import string
def tokenize(line):
table = dict.fromkeys(map(ord, string.punctuation))
return line.translate(table).lower().split()
In [185]:
words = ulysses.flatMap(lambda line: tokenize(line))
words.take(10)
[u'project', u'gutenbergs', u'a', u'portrait', u'of', u'the', u'artist', u'as', u'a', u'young']
In [186]:
words = words.map(lambda x: (x, 1))
words.take(10)
[(u'project', 1), (u'gutenbergs', 1), (u'a', 1), (u'portrait', 1), (u'of', 1), (u'the', 1), (u'artist', 1), (u'as', 1), (u'a', 1), (u'young', 1)]
In [187]:
counts = words.reduceByKey(lambda x, y: x+y)
counts.take(10)
[(u'aided', 1), (u'universalis', 1), (u'softhued', 1), (u'vita', 1), (u'pardon', 1), (u'believed', 3), (u'unheeded', 1), (u'resist', 1), (u'monte', 2), (u'yellow', 19)]
In [188]:
counts.takeOrdered(10, key=lambda x: -x[1])
[(u'the', 6052), (u'and', 3395), (u'of', 3259), (u'to', 2004), (u'a', 1986), (u'he', 1837), (u'his', 1743), (u'in', 1583), (u'was', 1066), (u'that', 951)]
Word count chained version¶
In [215]:
(
ulysses.flatMap(lambda line: tokenize(line))
.map(lambda word: (word, 1))
.reduceByKey(lambda x, y: x + y)
.takeOrdered(10, key=lambda x: -x[1])
)
[(u'the', 6052), (u'and', 3395), (u'of', 3259), (u'to', 2004), (u'a', 1986), (u'he', 1837), (u'his', 1743), (u'in', 1583), (u'was', 1066), (u'that', 951)]
Avoiding slow Python UDF tokenize¶
We will see how to to this in the DataFrames notebook.
CountByValue Action¶
If you are sure that the results will fit into memory, you can get a dacitonary of counts more easily.
In [190]:
wc = (
ulysses.
flatMap(lambda line: tokenize(line)).
countByValue()
)
In [191]:
wc['the']
6052
Persisting data¶
The top_word program will repeat ALL the computations each time we
take an action such as takeOrdered. We need to persist or
cache the results - they are similar except that persist gives
more control over how the data is retained.
In [192]:
counts.is_cached
False
In [193]:
counts.persist()
PythonRDD[244] at RDD at PythonRDD.scala:48
In [194]:
counts.is_cached
True
In [195]:
counts.takeOrdered(5, lambda x: -x[1])
[(u'the', 6052), (u'and', 3395), (u'of', 3259), (u'to', 2004), (u'a', 1986)]
In [196]:
counts.take(5)
[(u'aided', 1), (u'universalis', 1), (u'softhued', 1), (u'vita', 1), (u'pardon', 1)]
In [197]:
counts.takeOrdered(5, lambda x: x[0])
[(u'1', 6), (u'10', 1), (u'11', 1), (u'13', 1), (u'14', 1)]
In [198]:
counts.keys().take(5)
[u'aided', u'universalis', u'softhued', u'vita', u'pardon']
In [199]:
counts.values().take(5)
[1, 1, 1, 1, 1]
In [200]:
count_dict = counts.collectAsMap()
count_dict['circle']
1
In [201]:
counts.unpersist()
PythonRDD[244] at RDD at PythonRDD.scala:48
In [202]:
counts.is_cached
False
In [203]:
counts.cache()
PythonRDD[244] at RDD at PythonRDD.scala:48
In [204]:
counts.is_cached
True
Merging key, value datasets¶
We will build a second counts key: value RDD from another of Joyce’s works - Portrait of the Artist as a Young Man.
In [205]:
portrait = sc.textFile('/data/texts/Portrait.txt')
In [206]:
counts1 = (
portrait.flatMap(lambda line: tokenize(line))
.map(lambda x: (x, 1))
.reduceByKey(lambda x,y: x+y)
)
In [207]:
counts1.persist()
PythonRDD[256] at RDD at PythonRDD.scala:48
Combine counts for words found in both books¶
In [208]:
joined = counts.join(counts1)
In [209]:
joined.take(5)
[(u'aided', (1, 1)), (u'universalis', (1, 1)), (u'softhued', (1, 1)), (u'augustine', (2, 2)), (u'hats', (3, 3))]
sum counts over words¶
In [210]:
s = joined.mapValues(lambda x: x[0] + x[1])
s.take(5)
[(u'aided', 2), (u'universalis', 2), (u'softhued', 2), (u'augustine', 4), (u'hats', 6)]
average counts across books¶
In [211]:
avg = joined.mapValues(lambda x: np.mean(x))
avg.take(5)
[(u'aided', 1.0), (u'universalis', 1.0), (u'softhued', 1.0), (u'augustine', 2.0), (u'hats', 3.0)]